Autoregressive large language models generate text one token at a time. Each token waits for the one before it. This serial loop leaves modern GPUs underused and keeps inference slow. The cost grows worse with long Chain-of-Thought reasoning models. Their lengthy outputs make latency the dominant part of generation.
Speculative decoding is the standard fix. A small draft model proposes future tokens. The large target model verifies those tokens in parallel. Accepted tokens are kept, so the output stays lossless. But most methods, including the state-of-the-art EAGLE-3, still draft autoregressively. That serial drafting caps real-world speedups near 2–3×.
DFlash, introduced by research team from UC San Diego team (z-lab), takes a different route. It is a lightweight block diffusion model built for drafting. Instead of drafting tokens one at a time, it proposes a whole block in a single forward pass. The target model then verifies that block in parallel.
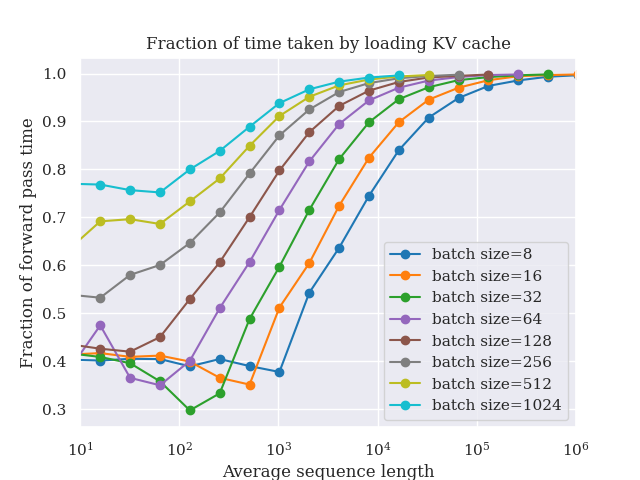
The research team reports over 6× lossless acceleration across a range of models and tasks. It reaches up to 2.5× higher speedup than EAGLE-3. On NVIDIA Blackwell, NVIDIA engineering team reports up to 15× higher throughput for gpt-oss-120b. That figure holds at the same user interactivity target.