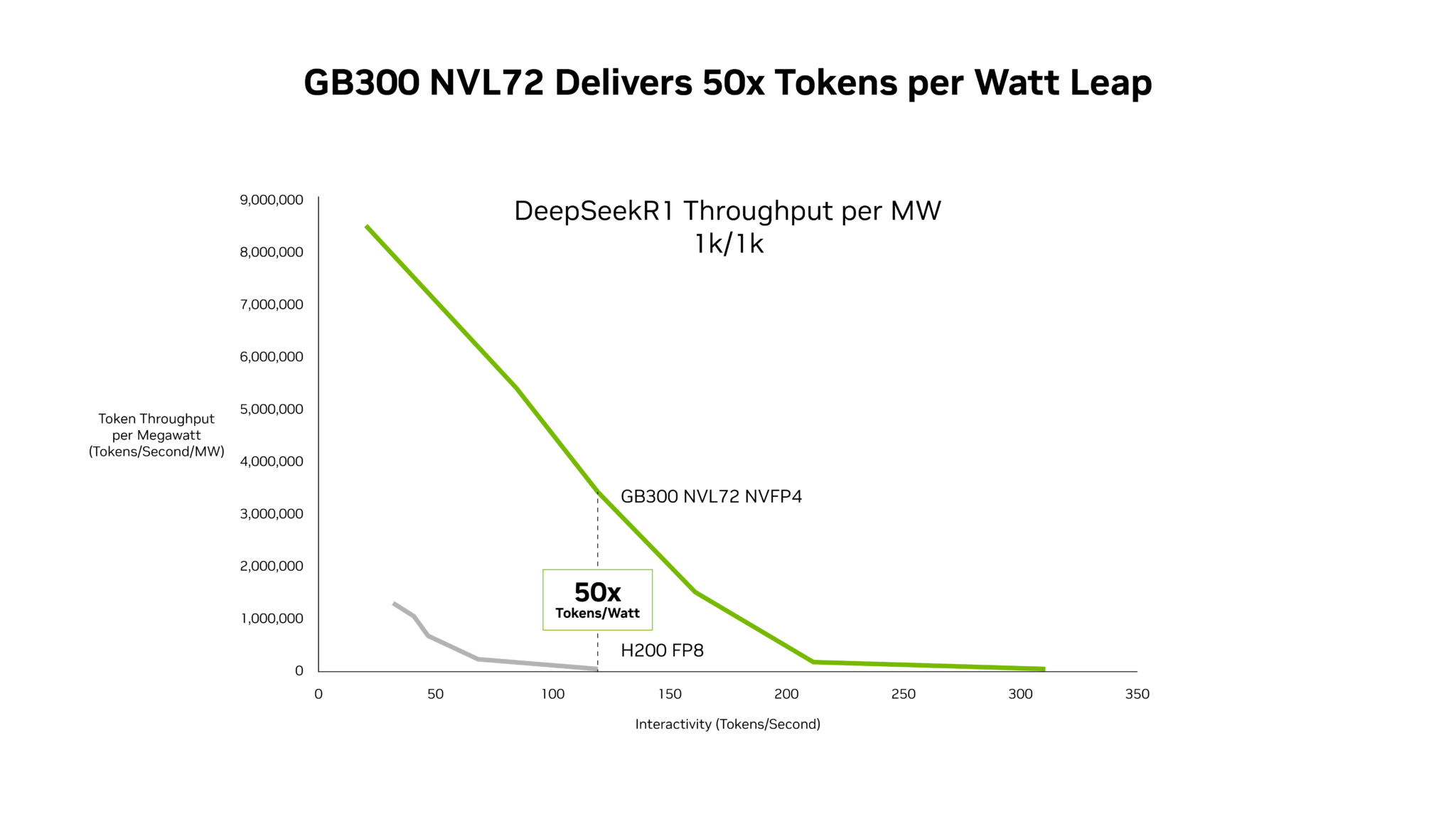
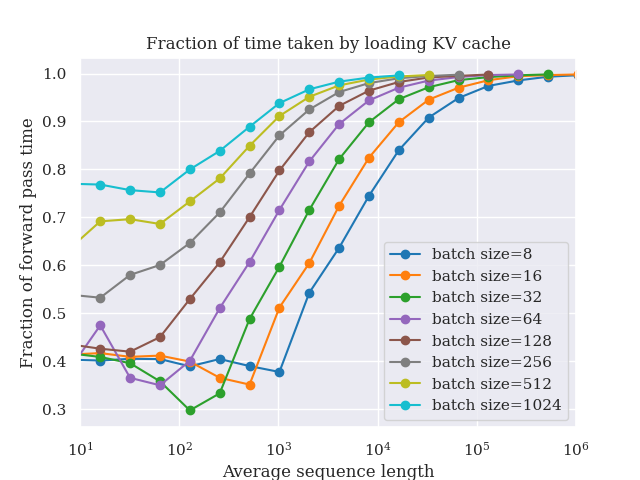
As AI systems move from single-turn interactions to coordinated multiagent workflows, low-latency inference becomes increasingly important. Autoregressive LLMs generate tokens sequentially, which can limit GPU utilization and constrain throughput in latency-sensitive serving scenarios.
Speculative decoding helps mitigate this bottleneck by using a lightweight model to draft future tokens, which the larger target model then verifies in parallel. DFlash is an open source lightweight block diffusion model designed for speculative decoding that extends this approach with a block-diffusion drafter. This drafter generates an entire block of candidate tokens in a single forward pass, turning sequential drafting into block-parallel GPU work while preserving the target model’s output quality through verification.
DFlash increases inference performance for gpt-oss-120b on NVIDIA Blackwell by up to 15x at the same interactivity level. It nearly doubles interactivity for Llama 3.1 8B at the same concurrency compared with state-of-the-art EAGLE-3 speculative decoding.
DFlash is also moving quickly from research into developer workflows. The research team has released 20 DFlash checkpoints on Hugging Face with recipes for NVIDIA Blackwell and NVIDIA Hopper GPUs.