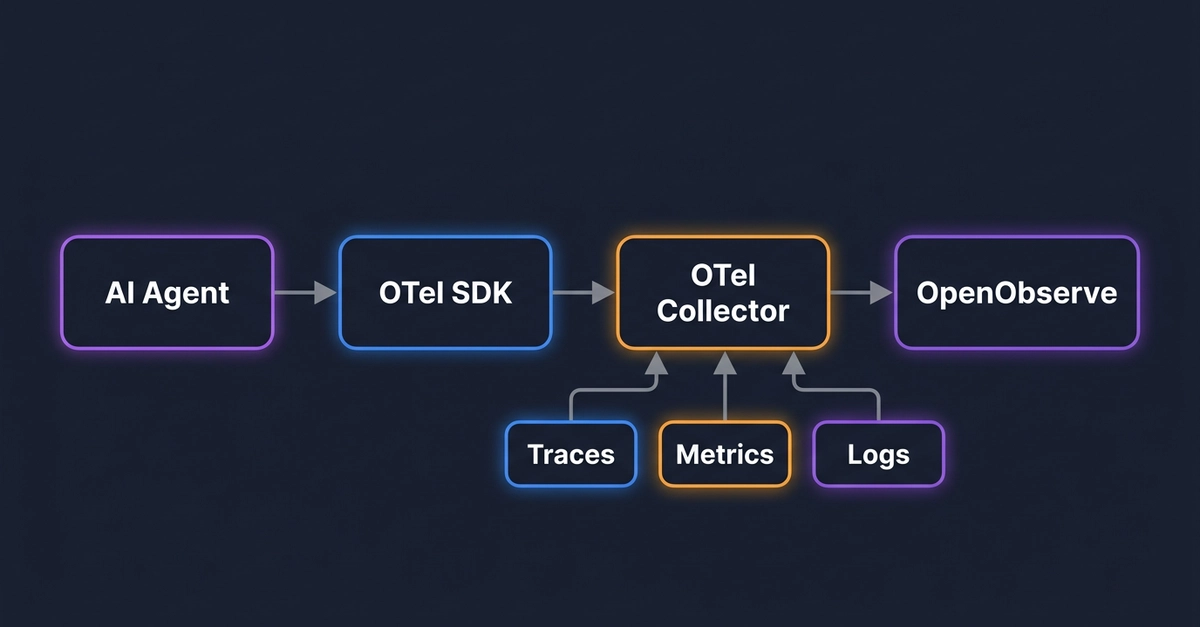
I added agent monitoring to the list of reporting work that has crossed over into SRE production infrastructure, which is annoying but real enough. The trace used to explain a single request. Now it has to carry the agent run through tool calls, subagents, sandboxes, services, approvals, retries, and side effects. It has to support SREs reading the trace a week or so after it happened, when no one remembers the details. The trace must support rollback and the other production troubleshooting work SREs do. And it must be understandable by an SRE who has not already read through the full raw event log for the agent run.
First off, Sarah Cat made the core point that managing and monitoring agents requires rethinking infrastructure because existing systems were not designed for agent scale. Then Harrison Chase added that the same point applies on the monitoring side. Charity Majors made the observability version sharper: there is a huge problem tracking long-running async AI sessions with the usual transaction and trace building blocks.
Observability for long-running agent sessions is turning into the storage, identity, retention, correlation and control-plane for the behavior of AI agents.