requirements
hugging face account https://huggingface.co/
Setup llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
cmake -S llama.cpp -B llama.cpp/build -DGGML_METAL=ON -DLLAMA_CURL=OFF
requirements hugging face account https://huggingface.co/ Setup...
requirements
hugging face account https://huggingface.co/
Setup llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
cmake -S llama.cpp -B llama.cpp/build -DGGML_METAL=ON -DLLAMA_CURL=OFF

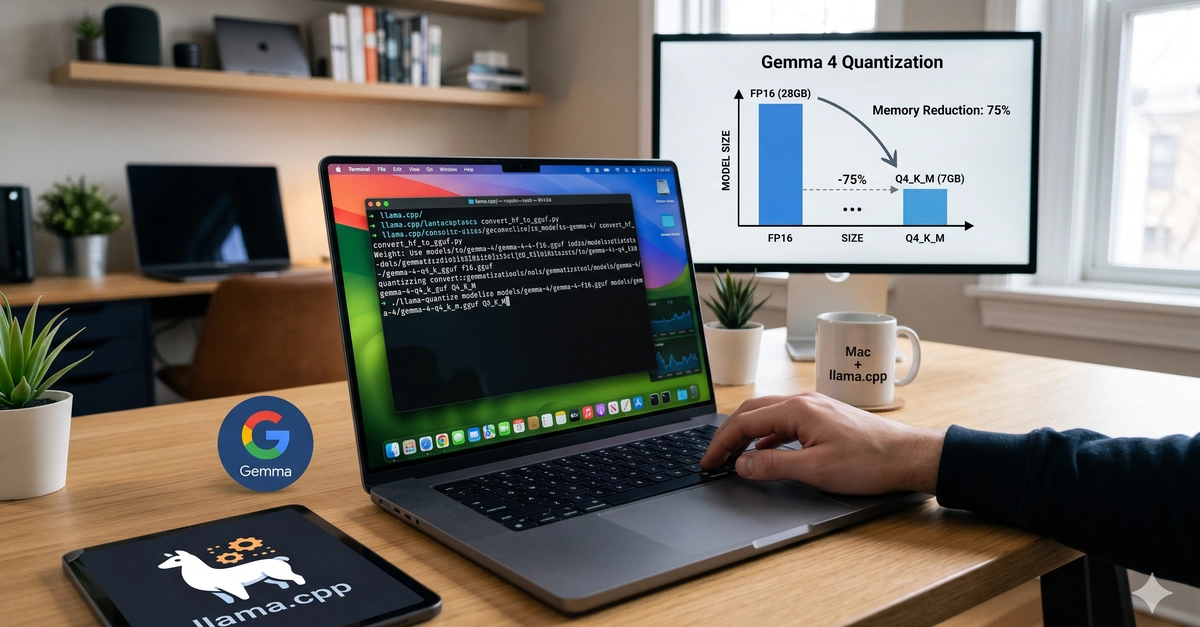
Tested Gemma-4 E2B-it on Raspberry Pi 4. the way to convert Gemma-4 E2B-it to gguf Quantizing...

This is a submission for the Gemma 4 Challenge: Write About Gemma 4 When local AI conversations...

In April 2026 Google shipped Gemma 4, a multimodal model with a native audio path. I wanted to add it...

1. update WSL environment sudo apt update && sudo apt upgrade -y Enter...

First steps: The usual first step with getting Gemma 4 running on Ollama is to pull the...
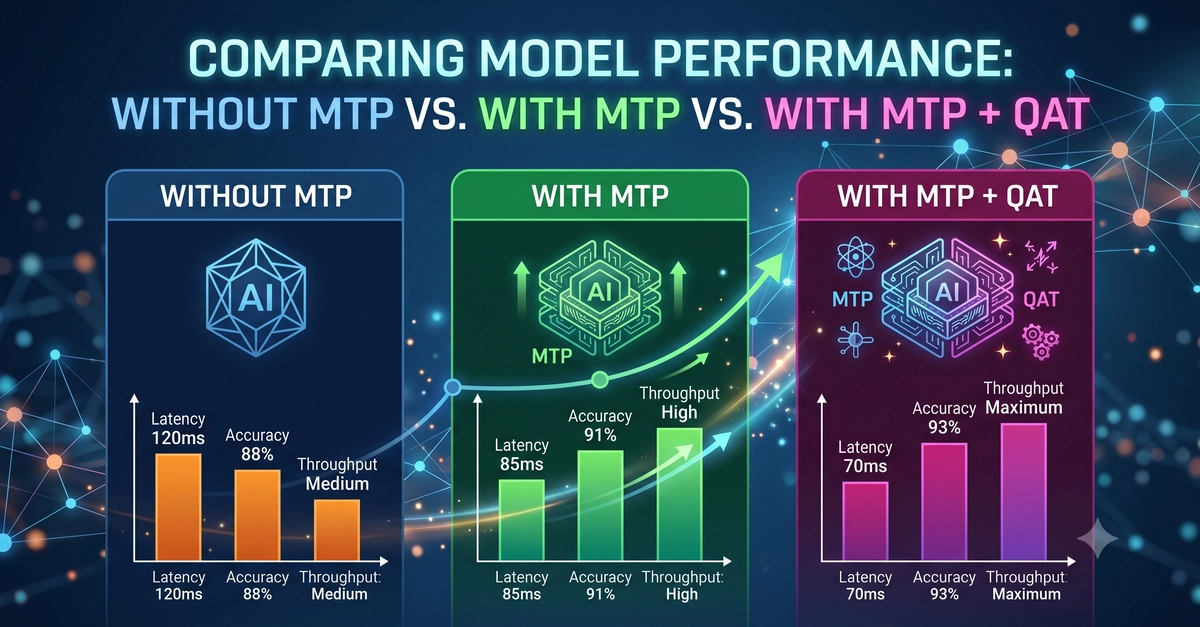
google--gemma-4-12B-it-Q4_K_M.gguf ...