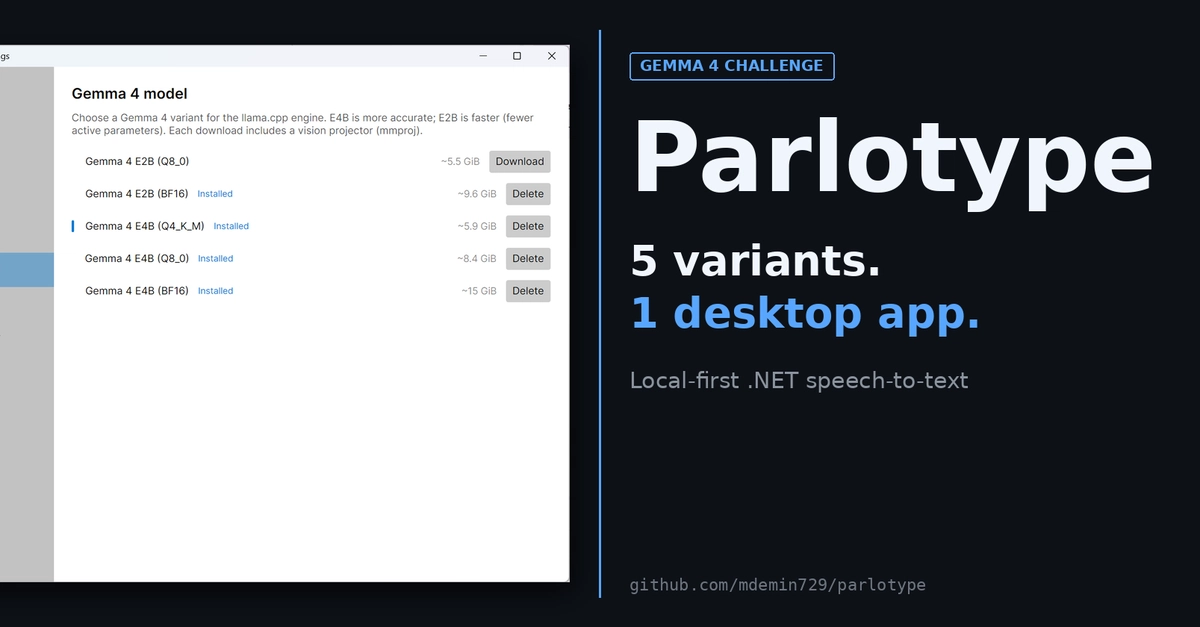
In April 2026 Google shipped Gemma 4, a multimodal model with a native audio path. I wanted to add it to Parlotype, my .NET 10 dictation app, as a second speech engine alongside Whisper. Four runtime paths got cut before I landed on llama.cpp's llama-server as a child process. This post walks through the cuts, the architecture that survived, the variant catalog, and the benchmarks.
Parlotype is a voice-to-text desktop app for Windows with on-device speech recognition as the default. You hold a global hotkey, speak, release. Text appears in whatever app you were typing into. This post is about adding a second on-device engine. Cloud speech providers are a separate, opt-in track and not the subject here.
This is the long companion to my Gemma 4 Challenge submission on the same topic. The challenge post is the 5-variant tour with the shipping decision. This one is the runtime selection and the architecture under it.
The constraints
Worth naming the constraints up front so the obvious answers make sense as dead-ends: