JUNE 3, 2026
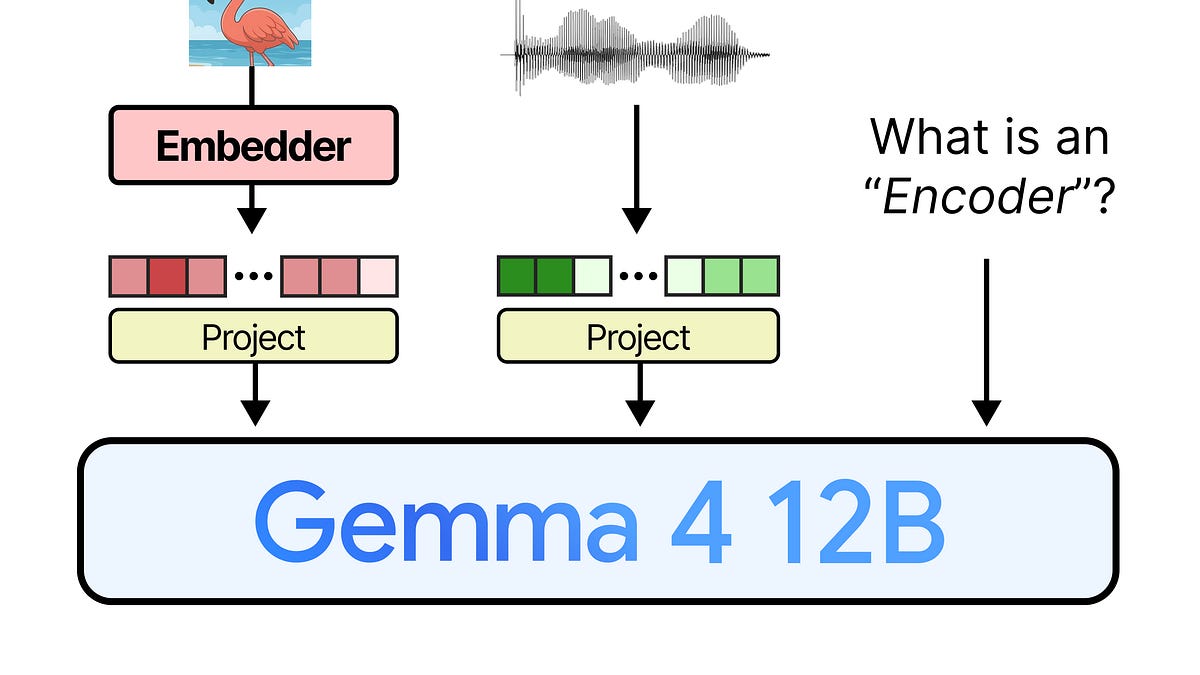
Following the announcement in our launch blog, we are releasing Gemma 4 12B, a dense multimodal model with a unified, encoder-free architecture.Gemma 4 12B introduces several milestones for local AI:A multimodal encoder-free architecture: Bypassing heavy multi-stage vision and audio encoders entirely, multimodal data is fed straight into the LLM backbone, reducing multimodal latency.Our first medium-sized model with audio input: In the Gemma family, audio inputs were restricted to small, lightweight edge architectures (e.g. E4B). Gemma 4 12B is the first medium-sized model capable of natively ingesting audio.Developer-friendly size: Small enough to run locally on dedicated GPU laptops with 16GB VRAM or unified memory. To maximize local inference speeds, we are additionally releasing a dedicated multi-token prediction (MTP) model.New MacOS desktop experience: For the first time, we are releasing downloadable macOS desktop applications, letting developers experience fully local spoken and visual interaction directly on consumer-grade devices.The ArchitectureTraditional multimodal models rely on frozen, separate vision encoders (e.g., Gemma 4 uses a 150M parameter vision model for edge sizes and 550M for medium-sized models) and audio encoders (300M parameters for Gemma 4 E2B and E4B). Processing multimodal inputs with multiple separate encoders before feeding them to the LLM leads to increased latency and fragmented memory footprints.Gemma 4 12B solves these issues by utilizing a single decoder-only transformer containing the same advanced decoder structure as the Gemma 4 31B Dense model.