
Tested Gemma-4 E2B-it on Raspberry Pi 4.
the way to convert Gemma-4 E2B-it to gguf
models
https://huggingface.co/baxin/gemma-4-E4B-it-E2B-it-Q4_K_M
llama.cpp
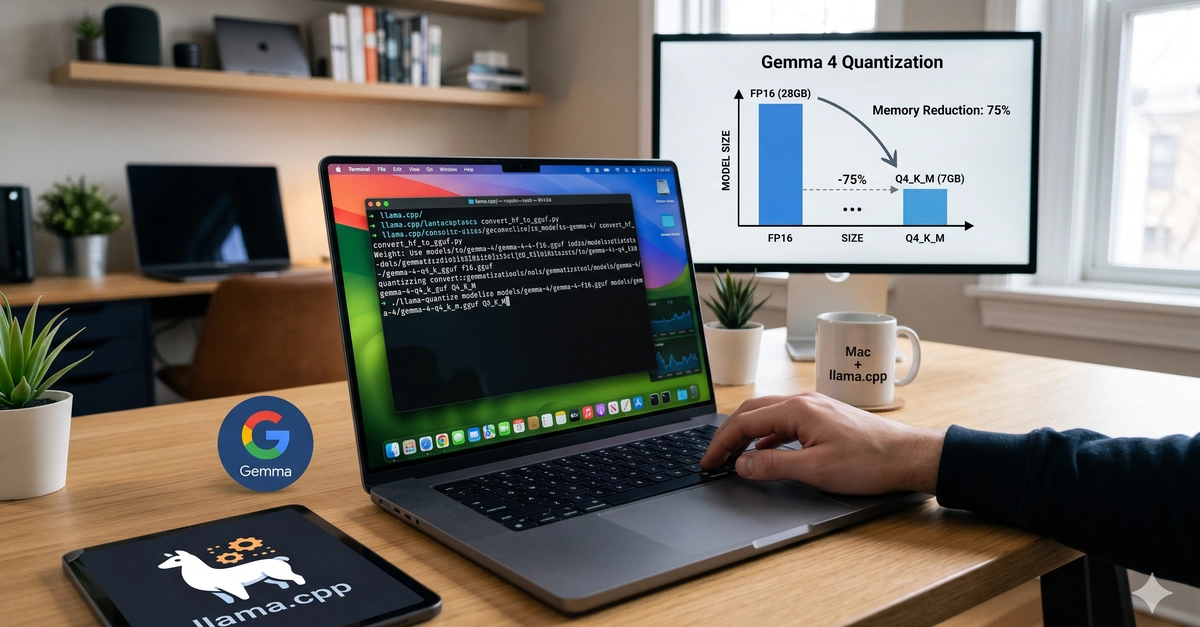
Tested Gemma-4 E2B-it on Raspberry Pi 4. the way to convert Gemma-4 E2B-it to gguf Quantizing...
Gemma-4 E2B-it (Q4_K_M) tested on Raspberry Pi 4 with llama.cpp reaches ~1.8 t/s generation — too slow for agentic workloads; LFM2.5-8B drops to just 0.5 t/s. At ~$305, a Pi 5 loses on price/performance vs. a $300–400 mini PC with 16GB RAM for sub-10B local inference.
Tested Gemma-4 E2B-it on Raspberry Pi 4.
the way to convert Gemma-4 E2B-it to gguf
models
https://huggingface.co/baxin/gemma-4-E4B-it-E2B-it-Q4_K_M
llama.cpp

First steps: The usual first step with getting Gemma 4 running on Ollama is to pull the...
requirements hugging face account https://huggingface.co/ Setup...

A field report on running Google's Gemma-4 on AWS Inferentia2: mixed attention heads, the vLLM / optimum-neuron / NxD dead-ends,…

This is a submission for the Gemma 4 Challenge: Write About Gemma 4 When local AI conversations...

This is a submission for the Gemma 4 Challenge: Write About Gemma 4 Google released four Gemma 4...

Hi Everyone, I’m back with a brand new project, and this one has been a long time coming. For a...
