TL;DR: We put Bifrost in front of the VLM step that captions and rewrites prompts for our product-photo diffusion pipeline. Semantic caching cut that bill by ~62% in three weeks. The diffusion side, where the GPUs live, was never the cost we should have been worrying about.
The bill that surprised us
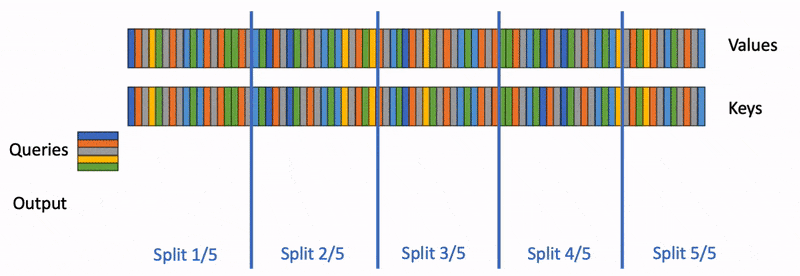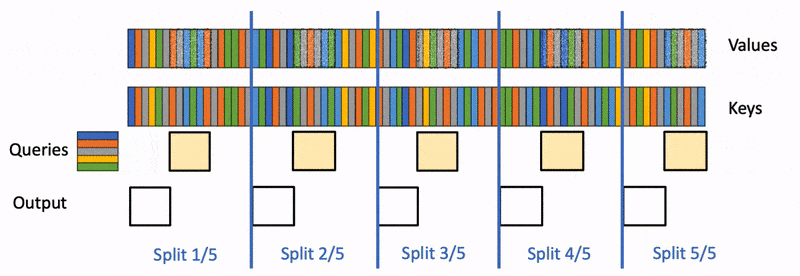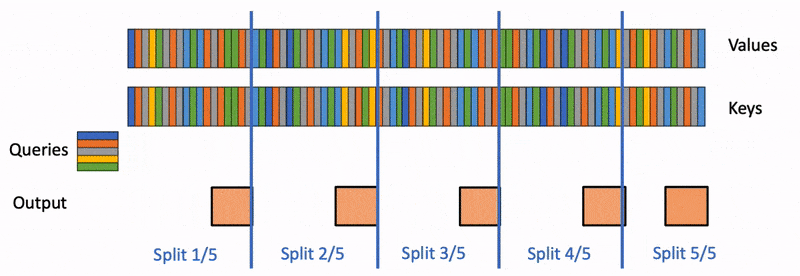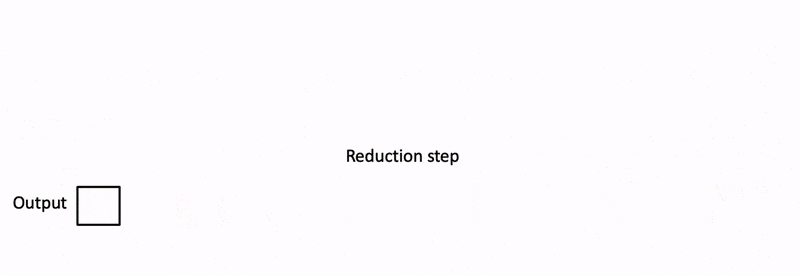
Our pipeline at Photoroom (paraphrased, not exact internal numbers) does three things per product image. A vision-language model reads the input and produces structured captions. A second LLM call rewrites the user's prompt into something the diffusion model behaves well with. Then SDXL with our internal LoRAs does the actual generation on our own A100s.
The diffusion step is what we obsess over. To be precise, it is what we benchmark and profile every sprint. So when we looked at the Q1 numbers, the surprise was that Claude and Gemini Vision together cost more than the GPU lease for the same workload. The VLM and prompt-rewrite layer was 58% of total inference spend.
The nuance here is that we had been calling the providers directly from a Python service with no caching. Same product image, same user request. The response paid for again.