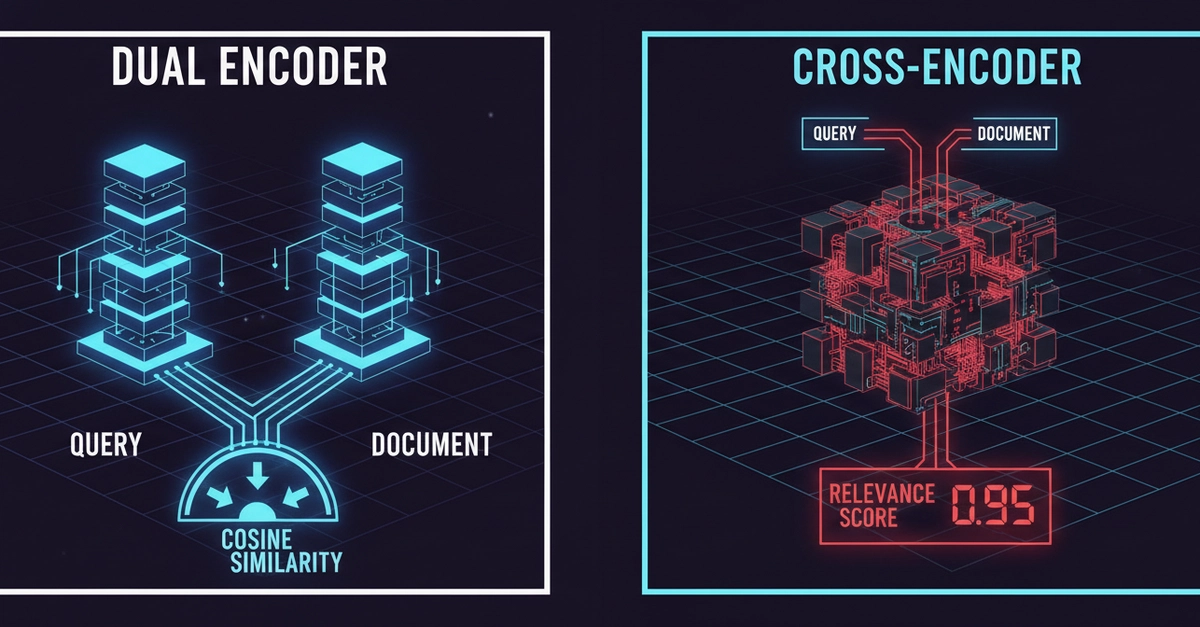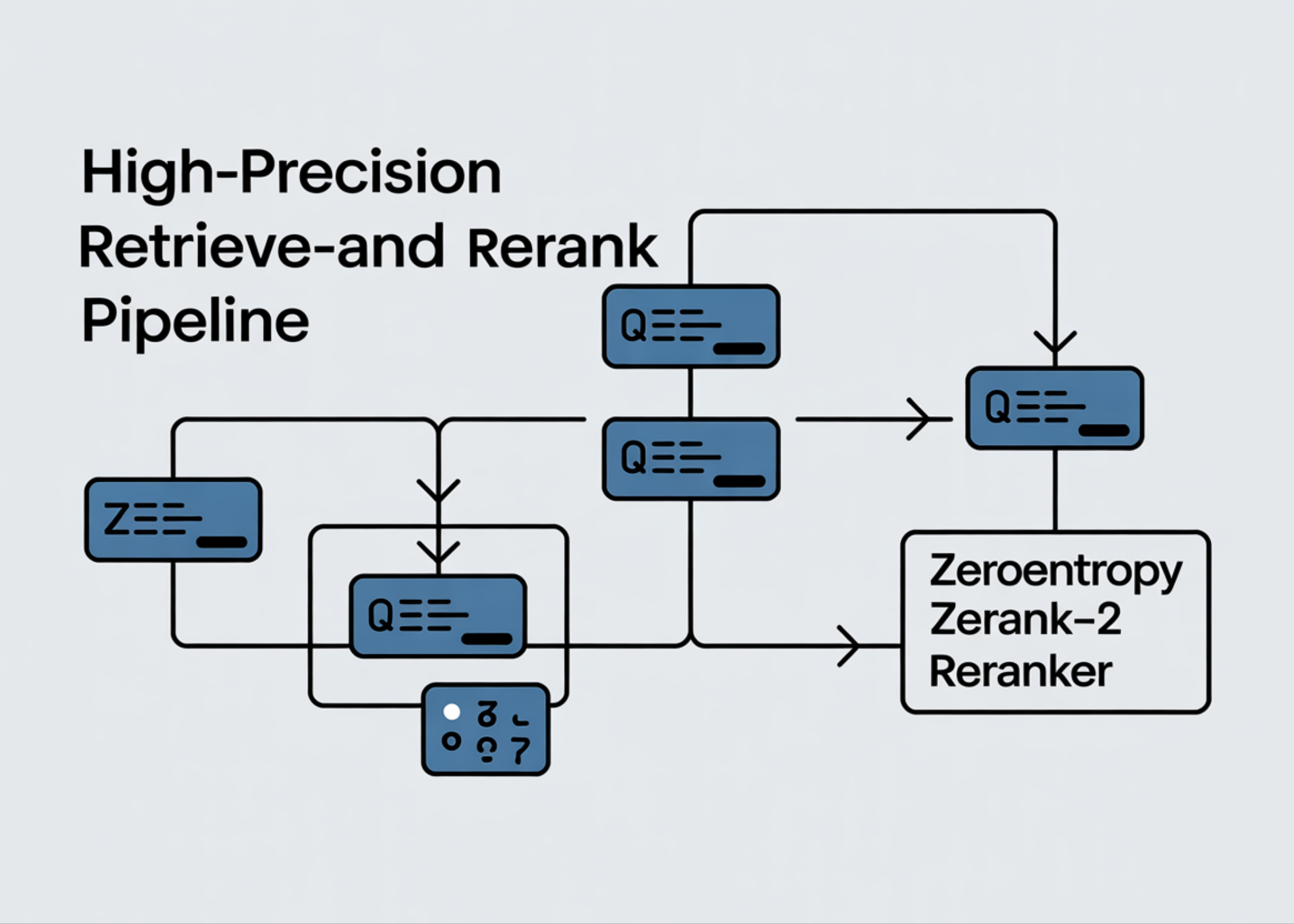
In this tutorial, we use zeroentropy/zerank-2-reranker, a 4B Qwen3-based cross-encoder reranker, to improve retrieval quality. We start by setting up the runtime, loading the reranker, and understanding how it scores query-document pairs. Then, we move from simple pairwise scoring to a practical two-stage retrieve-and-rerank pipeline, where a fast bi-encoder first retrieves candidates and zerank-2 reranks them for better precision. We also evaluate the impact using NDCG@10 and test the reranker across finance, legal, and code examples to assess its performance in real-world search and ranking tasks.
!pip -q install -U "sentence-transformers>=3.0" "transformers>=4.51.0" accelerate
import os, time, numpy as np, torch
from sentence_transformers import CrossEncoder, SentenceTransformer, util
os.environ["TOKENIZERS_PARALLELISM"] = "false"