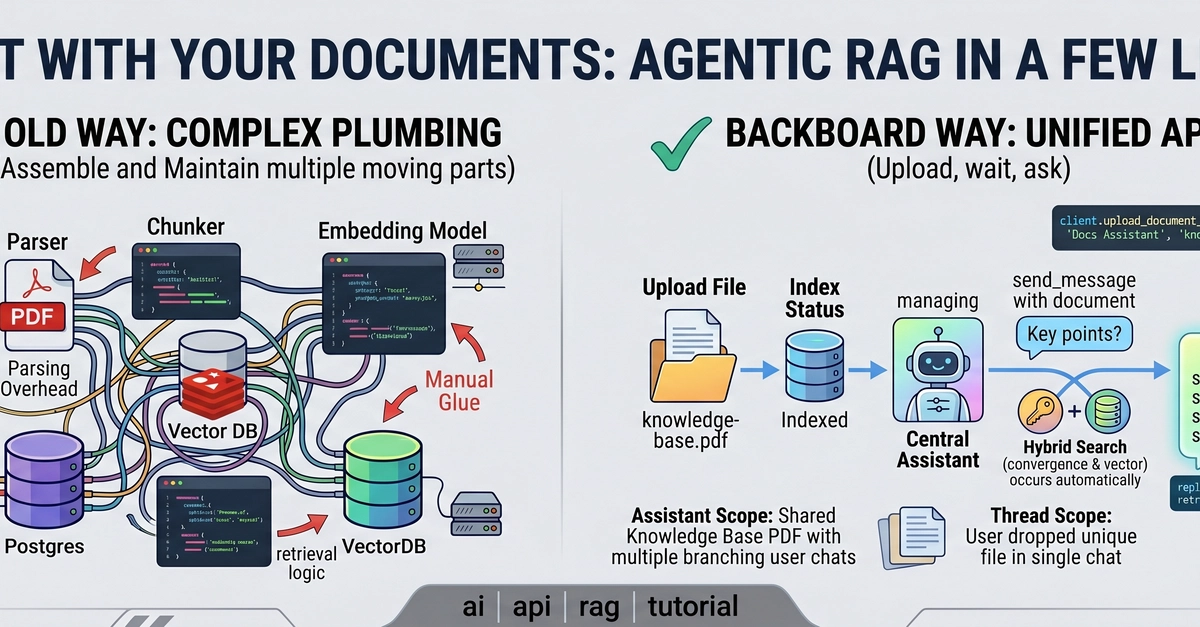
In Part 1, we built a USC campus assistant by pasting a five-line knowledge base directly into the prompt. That works when "the data" fits in your head. It stops being cute the moment the campus handbook, club docs, and workshop notes all want a seat at the same prompt window.
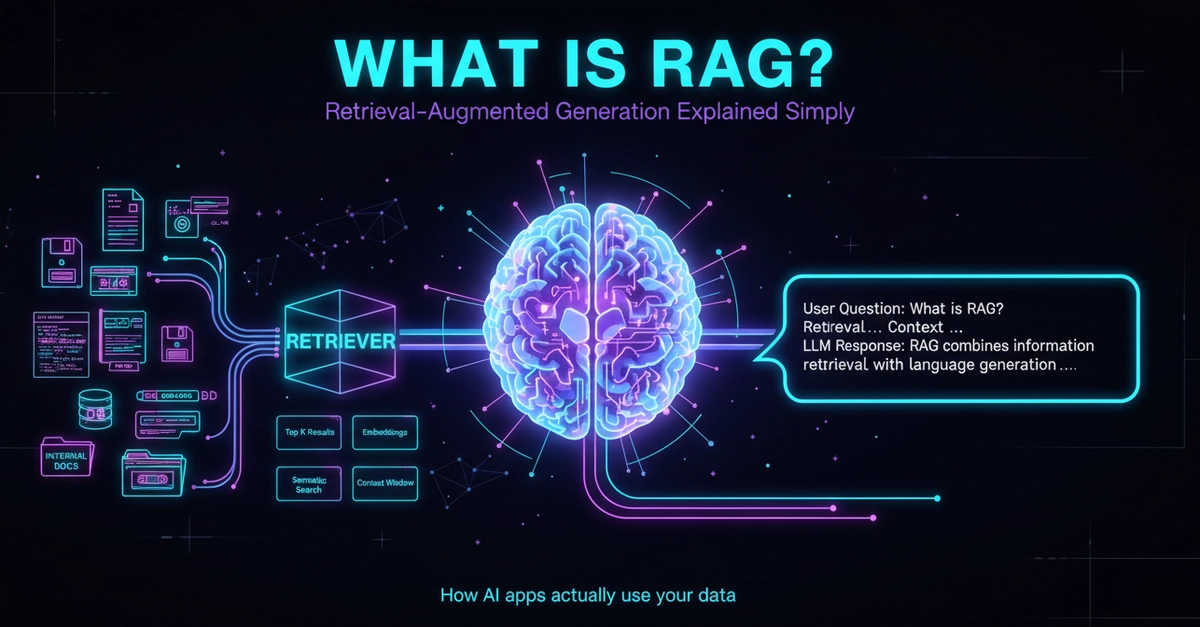
The fix is retrieval — store the chunks once, and at query time pull only the few that look relevant. That's what RAG (Retrieval-Augmented Generation) actually means once you strip away the marketing.
This post takes the assistant from Part 1 and bolts on a real retriever, using NVIDIA's hosted embedding model. No vector database, no LangChain, no abstraction layer. A Python list and NumPy are enough to understand what's actually happening. Once you've seen the moving parts, swapping in pgvector or Pinecone later is a fifteen-minute job.
I'm B Torkian, NVIDIA Developer Champion at USC. Same workshop series, same campus, one more capability added.
What you're adding