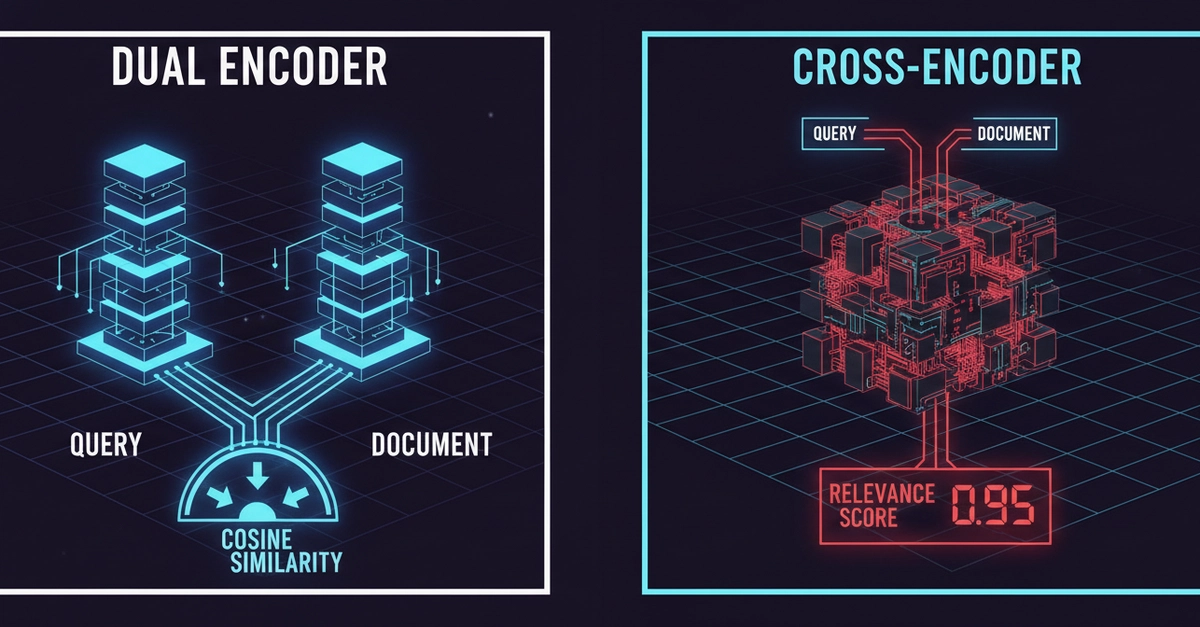
My RAG pipeline looked fine on paper. Fast retrieval. Decent cosine scores. But when I tested it with real queries, the top results were always a little off. Documents that shared vocabulary with the query kept showing up instead of documents that actually answered it. The model was doing its job. The architecture was not.
The fix was not a better model. It was a second model doing a different job.
This post breaks down what that means, why it matters, and how to build the two-stage pipeline in Python.
The Problem With Single-Stage Retrieval
Every search system faces a hard tradeoff between speed and accuracy.