Just because a language model nails a question about a PDF doesn't mean it actually found the answer where it claims to.
Researchers at Peking University and the Shanghai Artificial Intelligence Laboratory built a new benchmark called CiteVQA to expose this gap between getting the right answer and pointing to the right source. They call it "attribution hallucination."
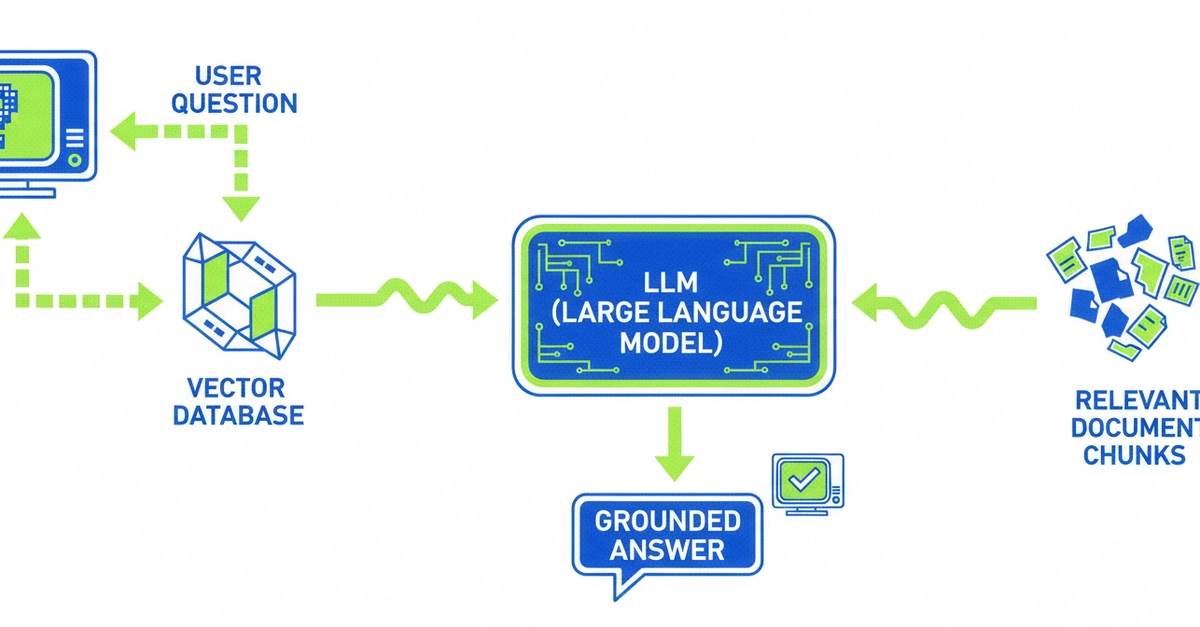
CiteVQA checks both the answer and the source location. A correct answer paired with a wrong citation gets an SAA score of 0 - only a correct citation counts. | Image: Ma et al.
Standard document analysis tests like DocVQA or MMLongBench-Doc only grade the final answer. They can't tell whether a model actually pulled information from the document or just guessed based on what it already knew. In law, financial audits, or medicine, though, traceability is what makes an AI output usable in the first place, the paper argues.
Pinpointing evidence