This is a submission for the Gemma 4 Challenge: Write About Gemma 4
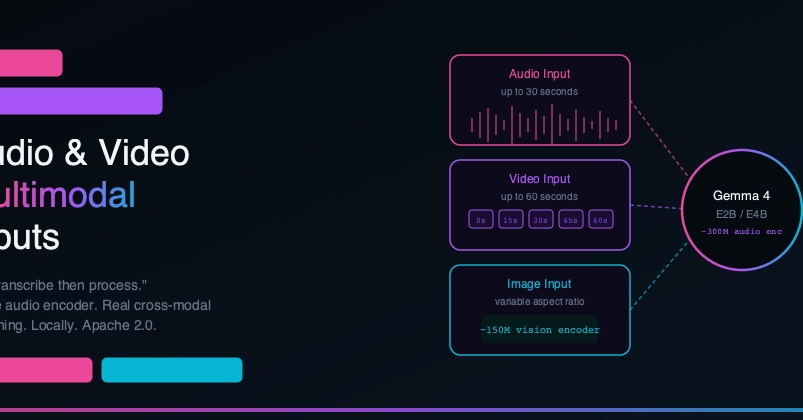
Most coverage of Gemma 4's multimodal capabilities stops at images. That's understandable — image input is the most obvious thing to demo. But Gemma 4 E2B and E4B ship with two more input modalities that are genuinely novel for a local, open-weight model: native audio input (up to 30 seconds) and video input (up to 60 seconds via frame sampling).
This guide covers what these actually support, how to use them in code, and what practical tasks they open up — with honest notes on where the current implementation has limits.
The Architecture: What Makes Audio Work
Audio input in E2B and E4B is handled by a dedicated encoder — a USM-style conformer with approximately 300M parameters, trained separately and connected to the language model via a projection layer.





