This is a submission for the Gemma 4 Challenge: Write About Gemma 4
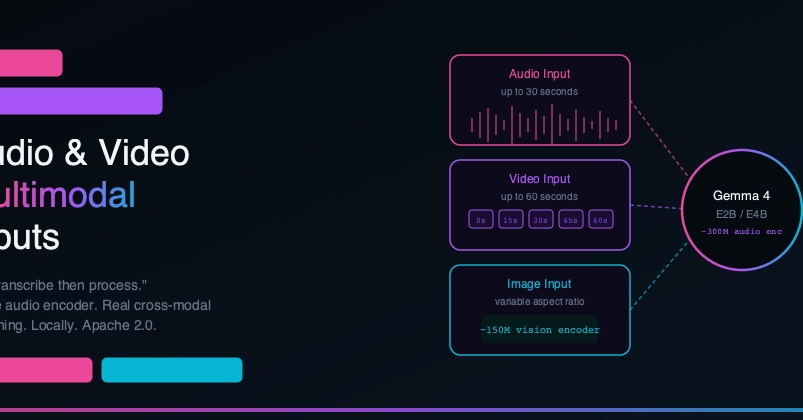
I was building Maatru, a Telugu literacy app for kids whose parents can't comfortably teach the script. The original design had photo-feedback as the core interaction. A kid writes a letter on paper, takes a picture, the app compares the writing to the target and gives feedback. The mechanic felt right. Paper-and-pencil is how kids actually learn handwriting. And Gemma 4's multimodal capability was one of the strongest things in the announcement.
Before I built anything, I tested whether the capability held up for my use case. It didn't. Gemma 4 confidently misread typed Telugu characters as completely different characters. These were clean Unicode glyphs on white backgrounds, the easy case. Across 20 test samples spanning four difficulty tiers, the cloud variant (Gemma 4 31B Dense) got 4 right. The local variant (Gemma 4 E4B) got 1.
The interesting part of this story isn't that the capability failed. It's that I knew within a day, not three weeks into the build. This essay is about the evaluation discipline that produced that knowledge. And why I think anyone planning to build a non-trivial product on Gemma 4 (or any model) should run capability gates before architectural commitment.