I tested Speculative decoding (Multi-Token Prediction, MTP) performance in Qwen 3.6 27B and 35B on an RTX 4080 with 16 GB VRAM.
For a broader view of token speeds and VRAM trade-offs across more models on the same hardware, see 16 GB VRAM LLM benchmarks with llama.cpp.
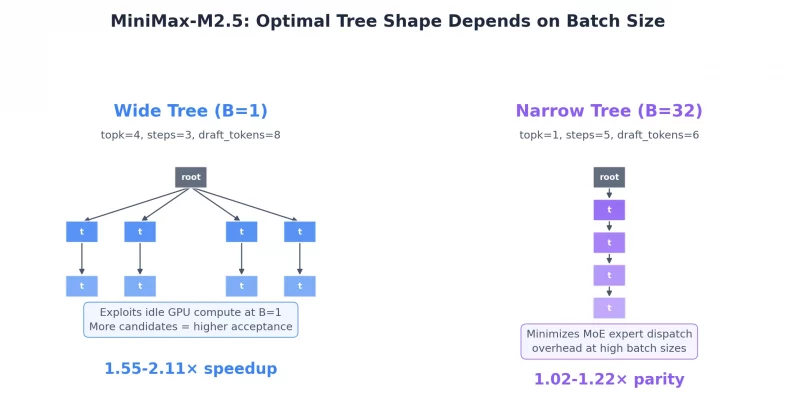
What MTP (Multi-Token Prediction) Is
Multi-Token Prediction is a form of speculative decoding built directly into certain model checkpoints. Instead of predicting one token per forward pass, the model carries extra "MTP heads" that propose several future tokens in a single step — then verifies them in parallel. If the guesses are accepted, the effective throughput rises without changing the output quality.
The Qwen 3.6 family ships both standard GGUF files and MTP-enabled variants. In llama.cpp, MTP is activated through: