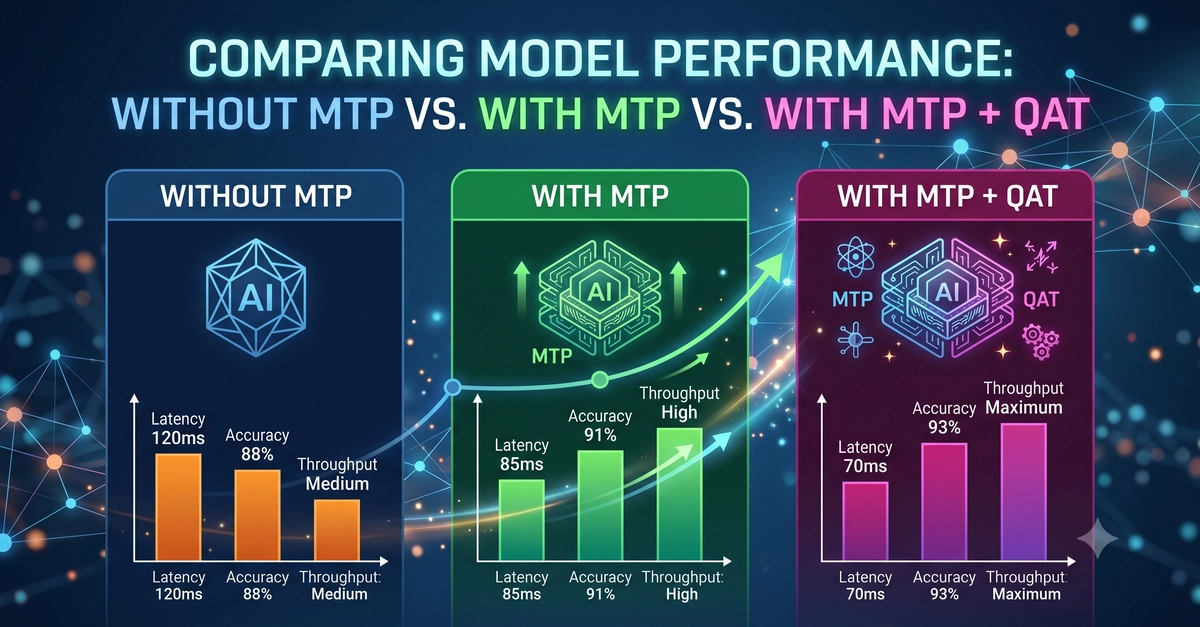
In my MTP post, speculative decoding roughly doubled Qwen3.6-27B generation on a 3090. It's tempting to read that as "turn on MTP, go faster." So I measured it on a different model — Gemma 4 12B QAT — and it's a big win on my 3090. But the same model with the same MTP draft runs slower on an M1 Max. MTP isn't a free switch; it's a hardware-dependent lever.
My 3090 numbers
Gemma 4 12B QAT (UD-Q4_K_XL) + an MTP draft head (Q8_0-MTP, a 0.47 GB nextn head, not a full second model), single RTX 3090, decode tok/s, 3 runs each:
config
mean tok/s