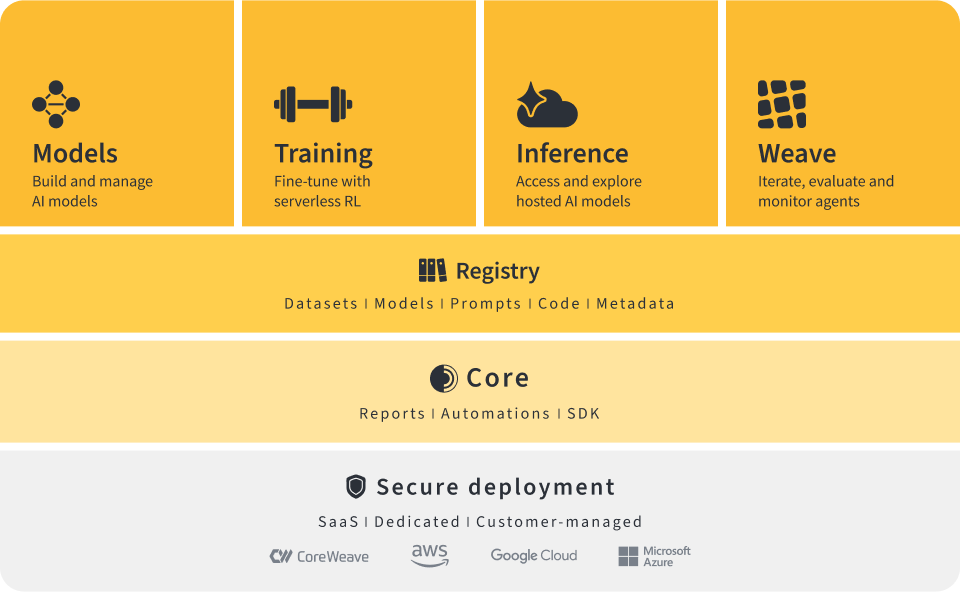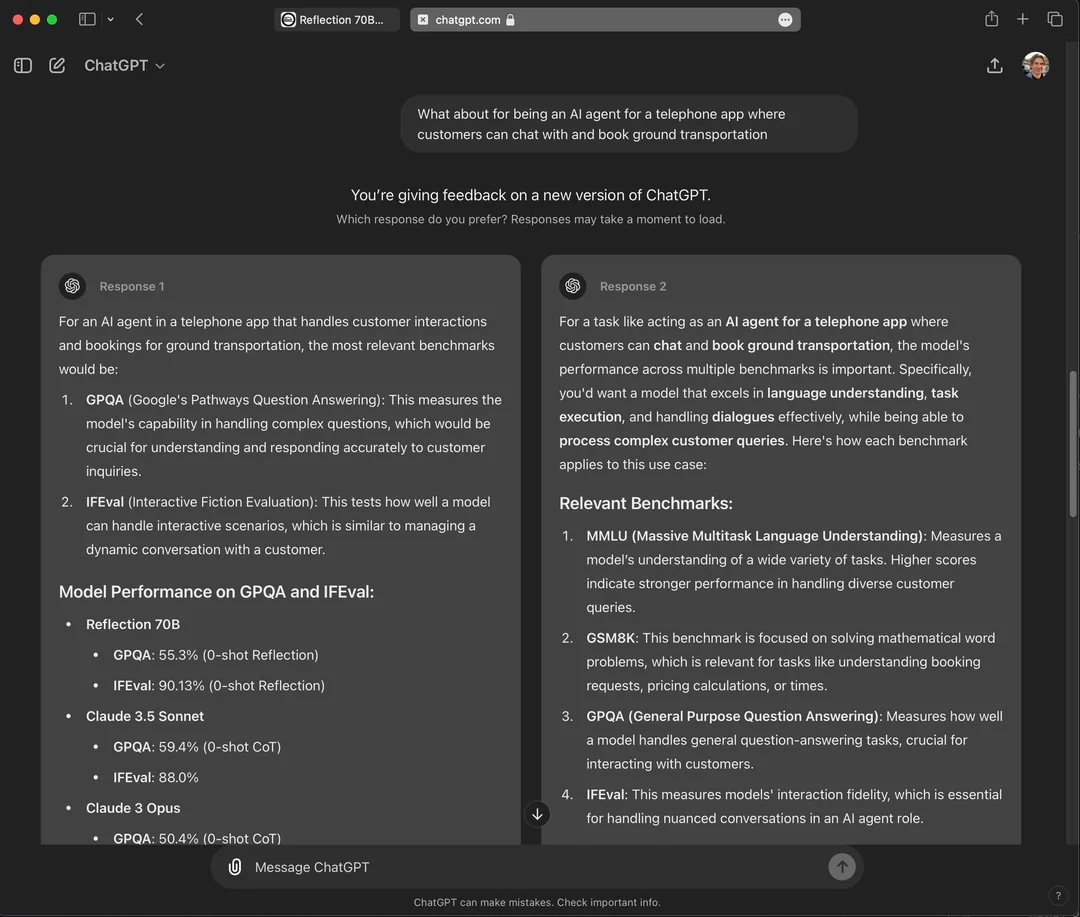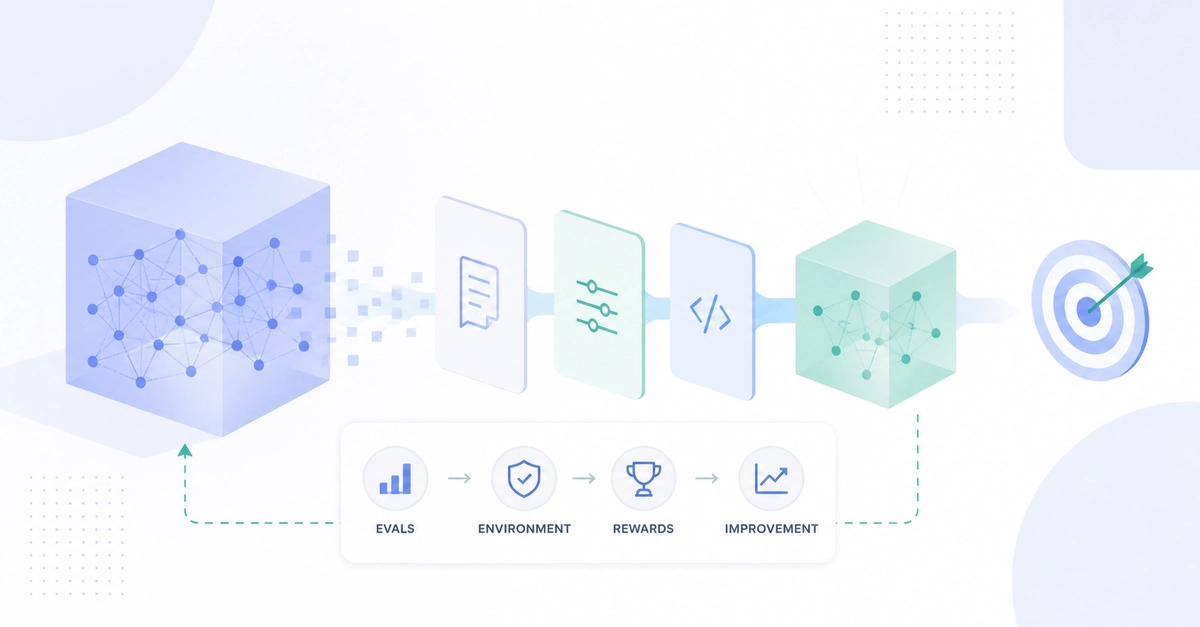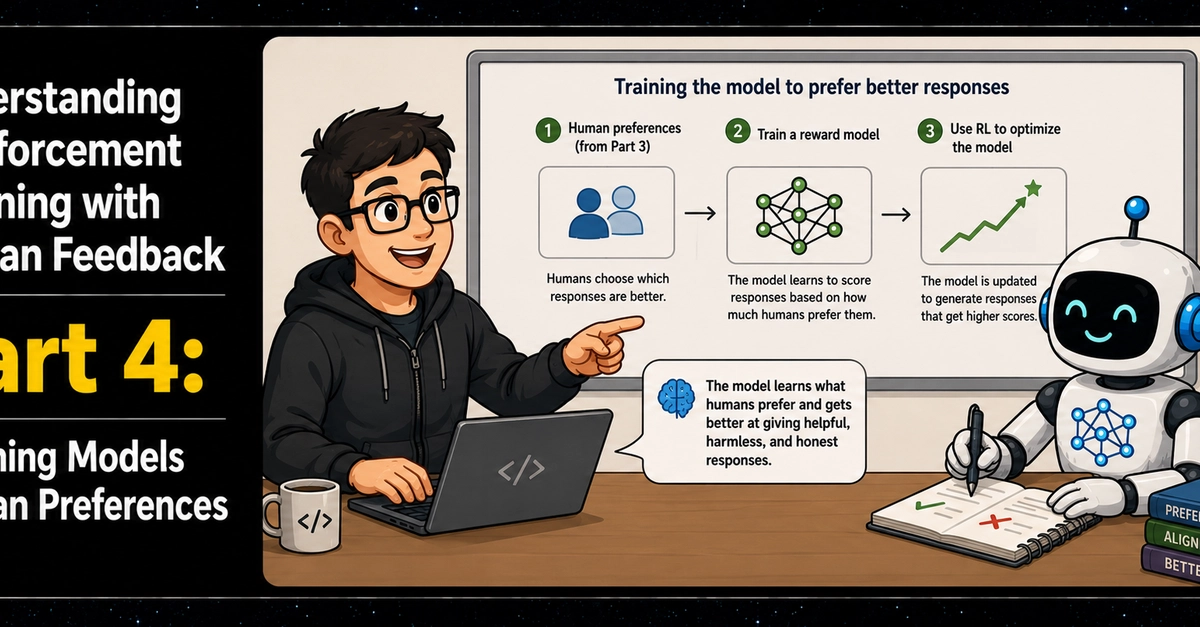
In the previous article, we explored the part where we collect human preferences. In this article, we will see how to use this data to train the models.
To train a model that gives higher scores to preferred responses, we first make a copy of the model that has already gone through supervised fine-tuning.
Modifying the Model
Next, we modify this copied model.
We remove the unembedding layer, which normally predicts the next token, and replace it with a single output value.