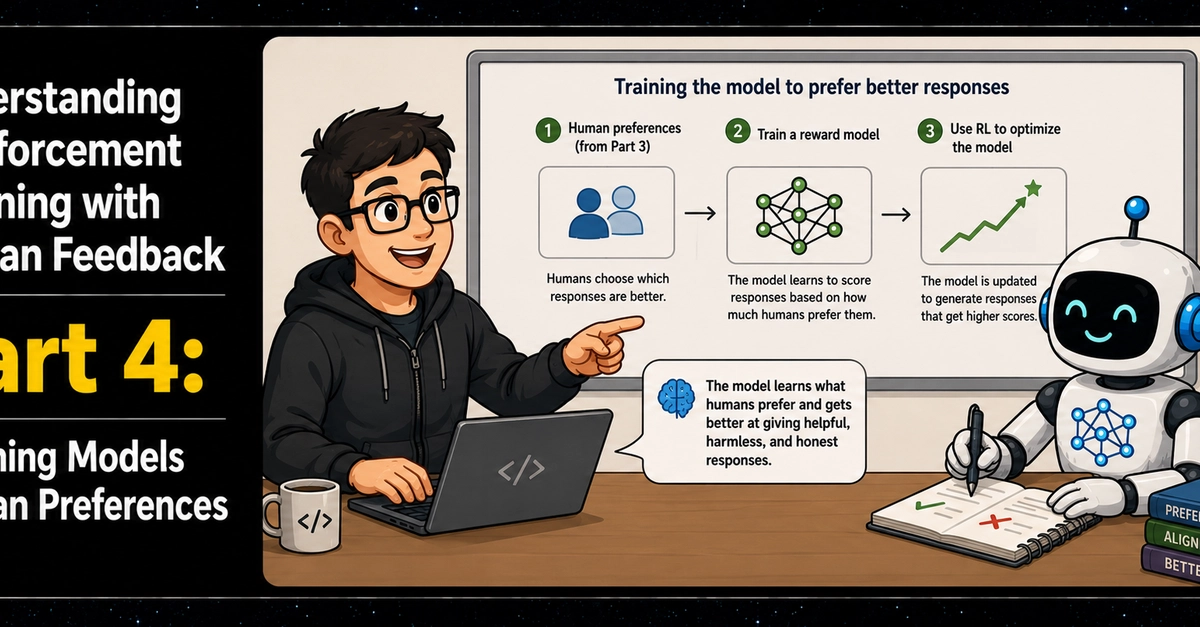
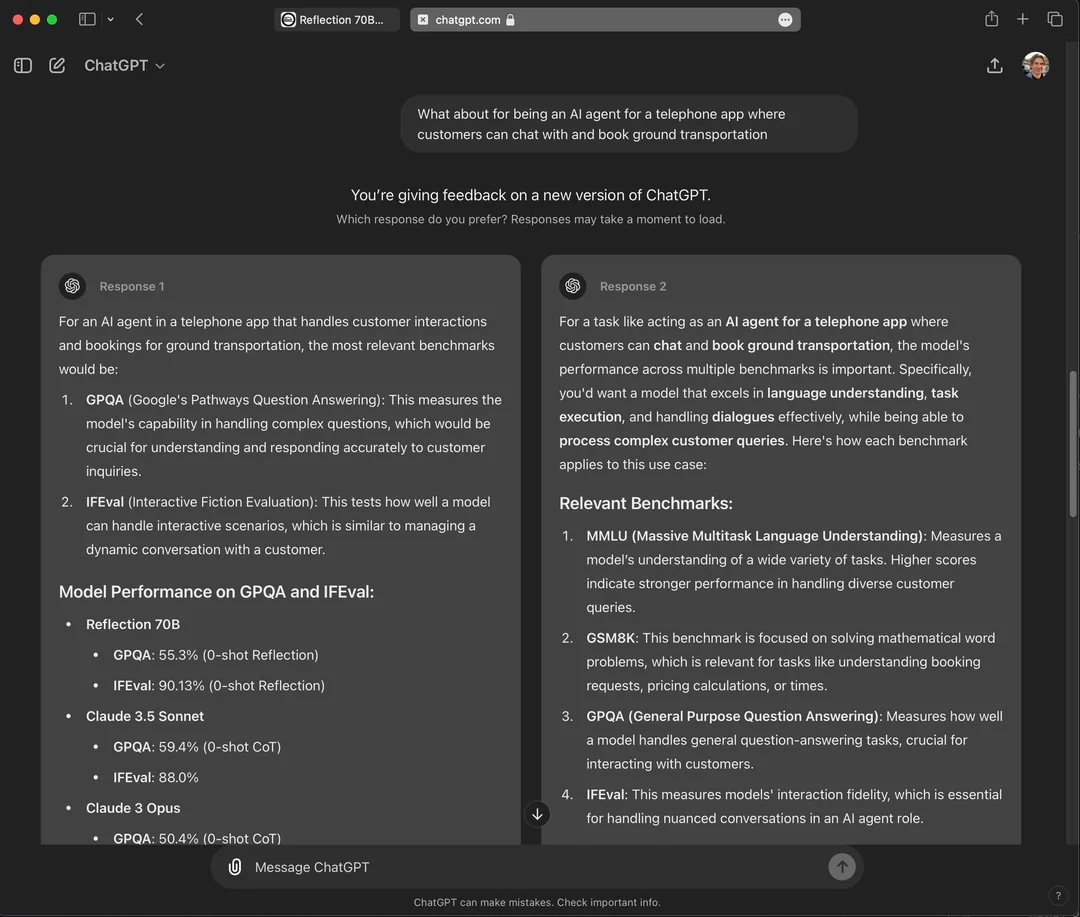
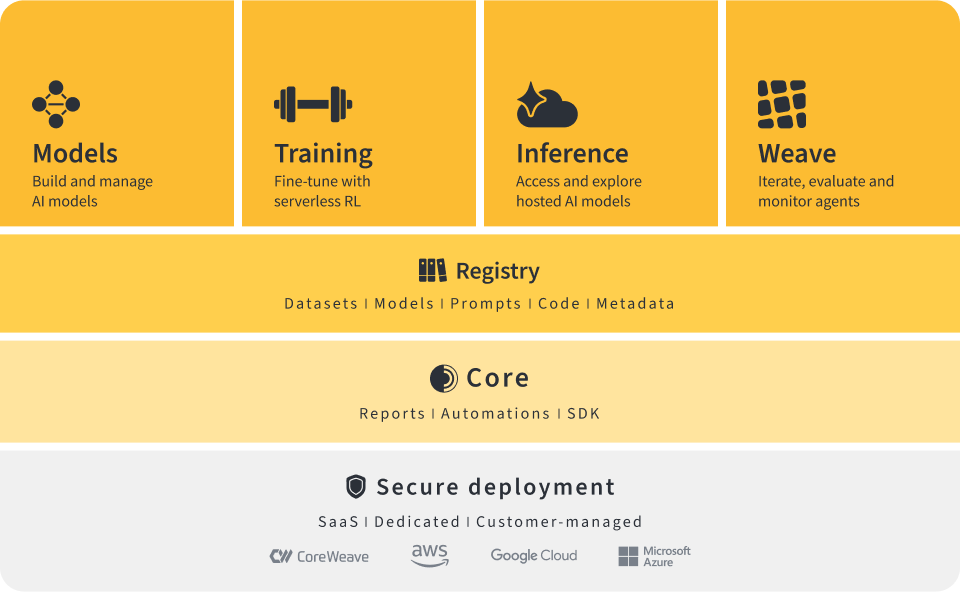
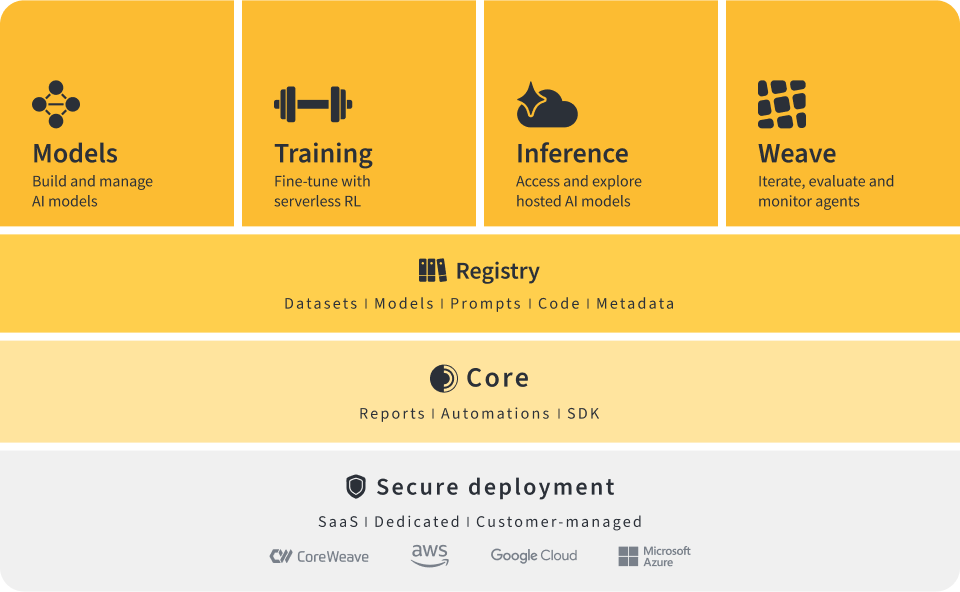
In the previous article we explored the concept of aligning the pretrained model. Now, we will look at the next component: human preference collection.
The first step in understanding RLHF is to understand that, given a specific prompt, a model can generate different responses.
One way to generate a response is to configure the model to always select the token with the highest output value at every step.
In this case, the model will generate the same response every single time for a given prompt.
Generating Different Responses