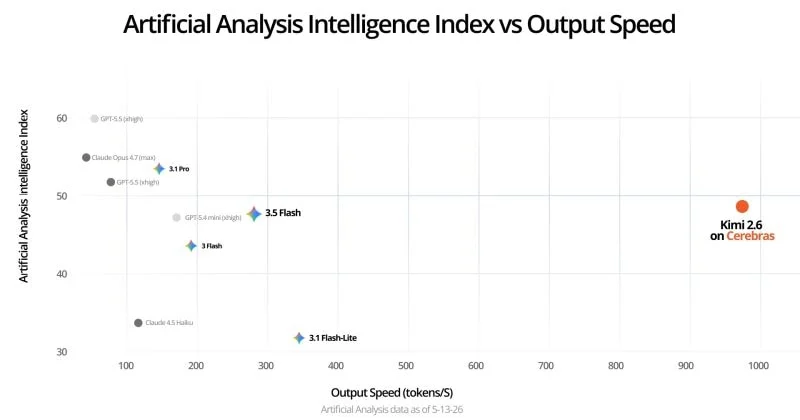
Cerebras Systems is now serving Moonshot AI’s Kimi K2.6, a 1-trillion-parameter open-weight Mixture-of-Experts model, at 981 output tokens per second. That number, verified by independent testing from Artificial Analysis, represents 6.7 times the speed of the next-best GPU cloud provider.
For context, the median inference provider clocks in at roughly 23 times slower.
What the numbers actually look like in practice
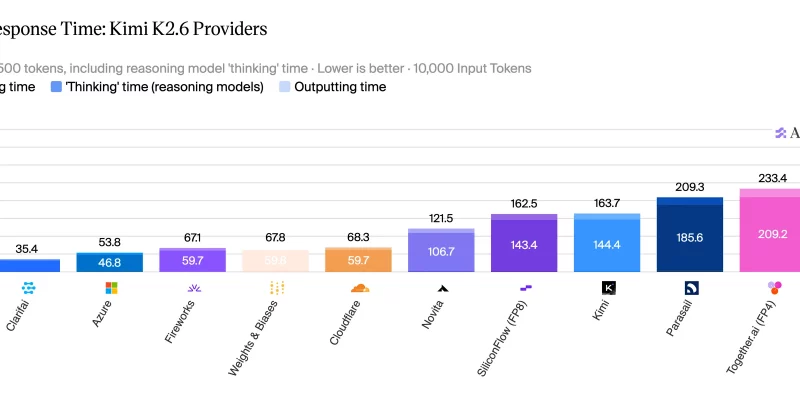
On a representative agentic coding workload, with 10,000 input tokens and 500 output tokens, the Cerebras-powered setup delivered a complete response in 5.6 seconds.
The same task on the official Kimi endpoint took 163.7 seconds. That’s a 29x improvement in end-to-end latency.