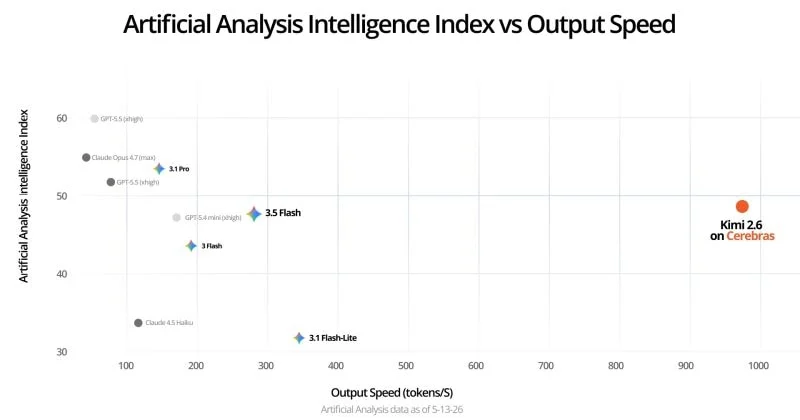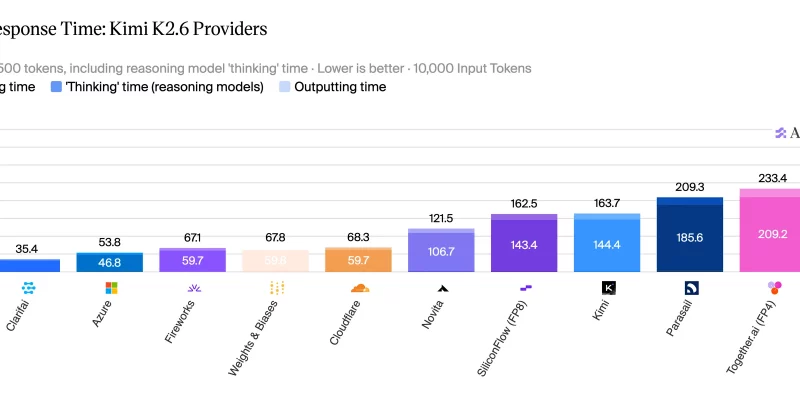
Cerebras Systems just posted the kind of benchmark that makes GPU cloud providers uncomfortable. The company’s inference platform is running Kimi K2.6, a trillion-parameter AI model, at 981 output tokens per second. That’s roughly 6.7 times faster than the next-best GPU cloud provider and 23 times faster than the median, according to benchmarking data from Artificial Analysis.
To put that in human terms: imagine reading a dense technical document and having an AI generate coherent, useful responses nearly seven times faster than the best alternative on the market. For enterprises building products on top of large language models, that kind of speed difference isn’t incremental. It’s architectural.
What Cerebras actually pulled off
Kimi K2.6 is built on Moonshot AI’s Kimi K2 family and uses a Mixture-of-Experts (MoE) architecture. Think of MoE as a team of specialists rather than one generalist: instead of activating every parameter for every input, the model routes each token through 32 of its many experts, keeping things efficient despite the model’s enormous size. A trillion parameters is, for context, roughly six times the size of GPT-3 and places Kimi K2.6 among the largest models currently in deployment anywhere.