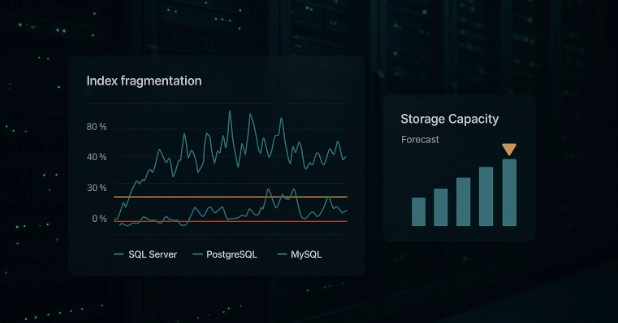
Database maintenance fails when it runs on a calendar instead of on signal. Fragmentation, stale statistics, log growth, and lock contention are functions of write workload, not weekly schedules. Scheduled maintenance skips the tables that need it most, and the resulting incident fires before anyone notices the gap.
This article replaces the cron job with a response system. Four observable symptoms (I/O degradation, query plan regression, storage pressure, and lock contention) each trace back to a specific maintenance root cause, with fixes for SQL Server, PostgreSQL, and MySQL. Silent corruption, the one failure mode that produces no precursor signal, gets its own detection-first treatment. A closing scorecard lets you self-assess.
First Response: Wait State Triage Across Engines
When a slow query alert fires, the first diagnostic step is the same regardless of engine: check what the query is waiting on. Wait states are the universal entry point for database incident triage. They tell you whether the problem is I/O bound, lock bound, or CPU bound, and that classification determines which section of this article contains your fix.
SQL Server wait types