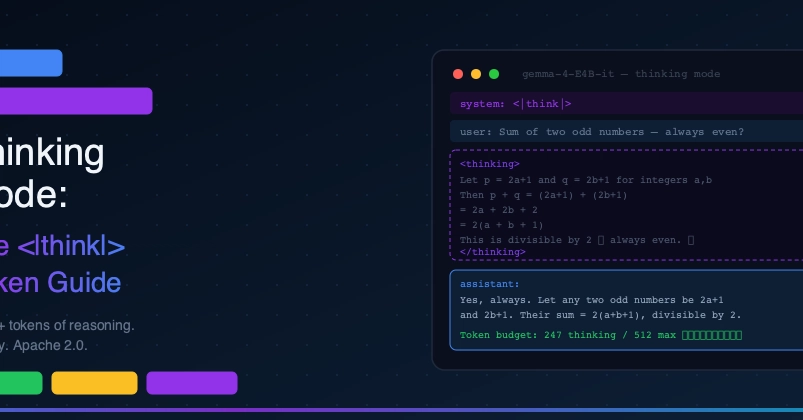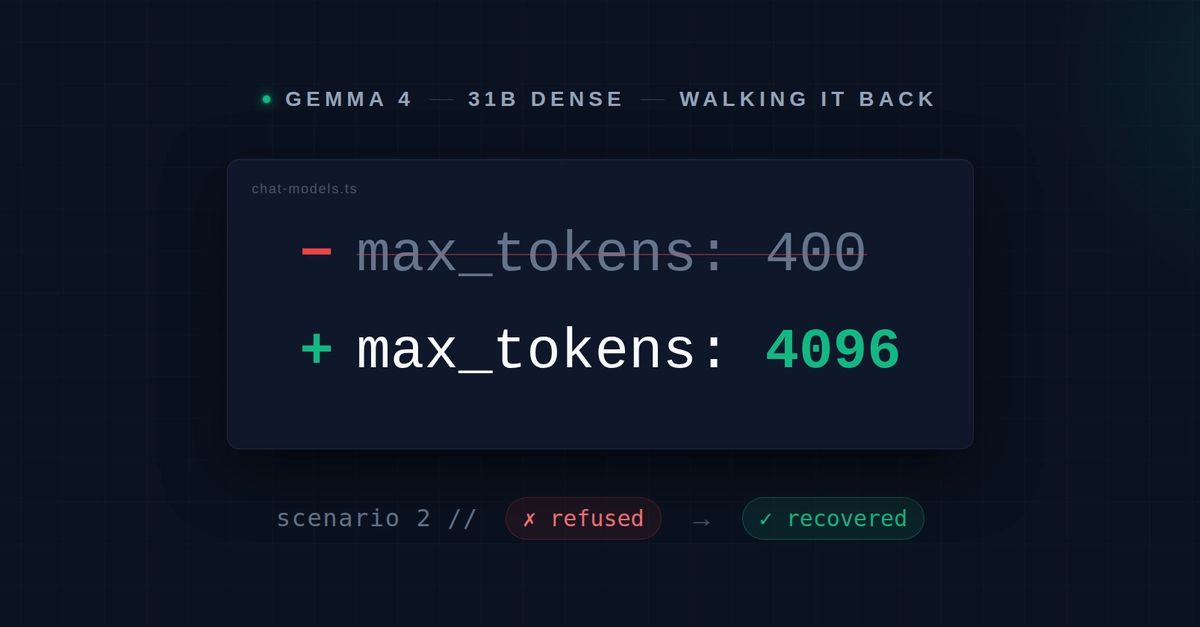
TL;DR: Last week I argued Gemma 4 Dense regressed on a grounded-retrieval scenario under tightened prompts — and called the MoE-vs-Dense divergence architecture-mediated. The comment thread, led by Robin Converse on her sovereign Ollama stack, proposed an alternative: my max_tokens: 400 cap was starving Gemma's reasoning layer before the visible reply completed. I re-ran the same six scenarios with one variable changed — budget raised from 400 to 4096. Dense recovered on every scenario, including the false-refusal headline that anchored the original article. MoE did too. The original MoE-vs-Dense divergence largely disappears when reasoning has room to finish. The cap was doing the work. Walking it back publicly.
Why I Re-Ran It
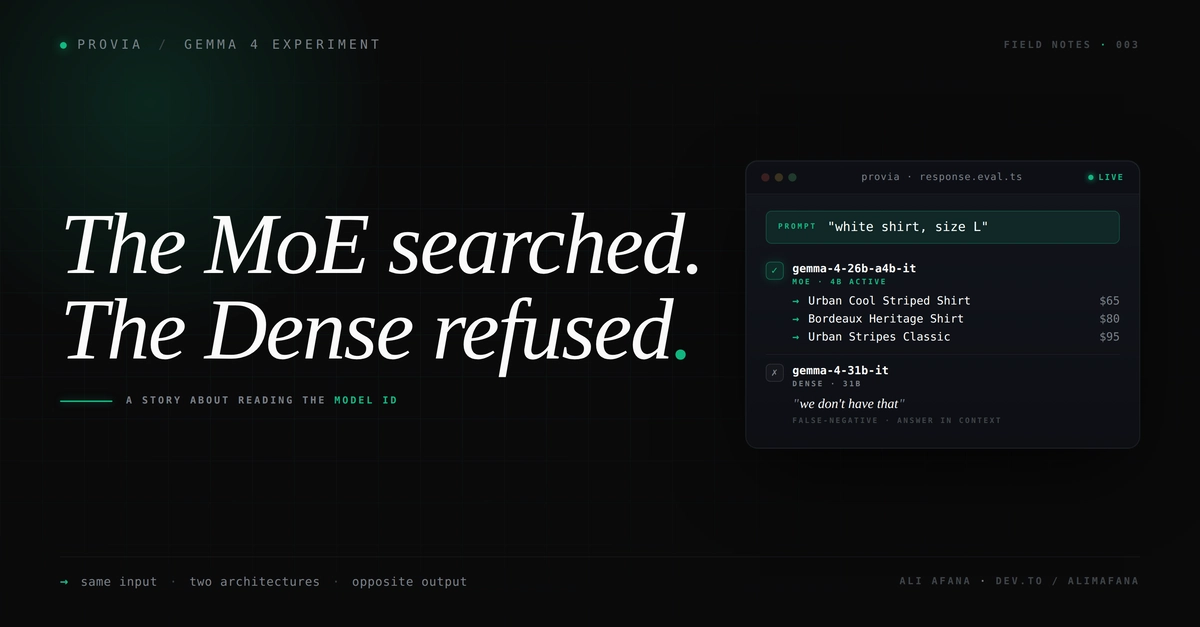
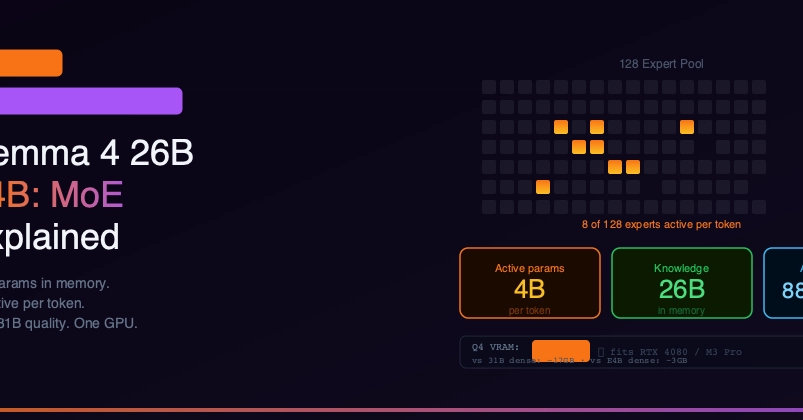
Last week I published I Added Three Rules to Gemma 4. The MoE Searched. The Dense Model Refused.. Quick recap: I ran Gemma 4 26B MoE and Gemma 4 31B Dense through my Arabic e-commerce chat router with three prompt rules — an Arabic-first system frame, temperature capped at 0.3, max_tokens floored at 400. The 26B MoE flipped from stalling to grounded answers. The 31B Dense flipped from working correctly to false-negative refusals on a scenario where the white shirts the customer asked about were sitting in its context. I called the divergence architecture-mediated and shipped the article.