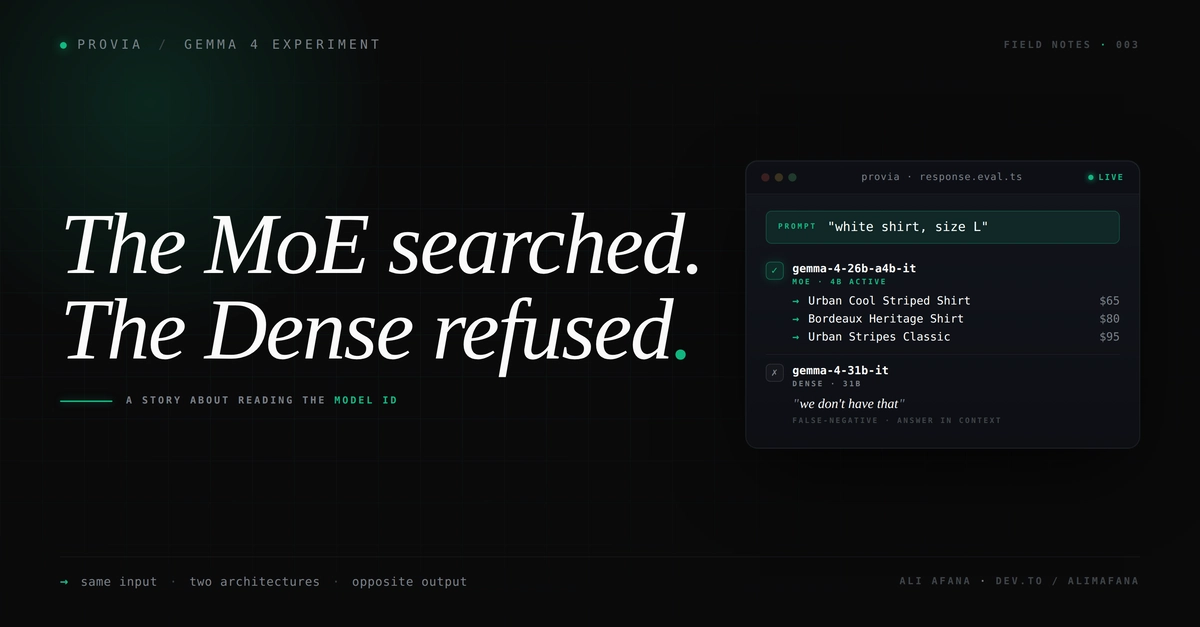
TL;DR: I run an AI sales chatbot for Arabic-speaking merchants. I wanted to know if Gemma 4 could replace GPT-4o-mini on the customer-facing reply. I tested two Gemma 4 variants — the 26B mixture-of-experts (4B active params) and the 31B dense model — against GPT-4o-mini and GPT-4o, across six Arabic customer scenarios, through my real production chat router. The actual failure mode of both Gemma variants in Round 1 wasn't hallucination. It was reluctance — stalling instead of searching, hedging instead of naming. So in Round 2 I added three Gemma-only prompt rules. The MoE flipped toward grounded answers. The dense model flipped toward false-negative refusals — claiming "we don't have that" with the answer sitting in its context. Same instructions, two architectures, opposite directions. I think I was tuning architecture, not size.
The Setup
My platform is a multi-tenant chat router for Arabic e-commerce. A customer message comes in; a small gpt-4o-mini router call decides whether to search products or just talk; if search runs, a second call writes the customer-facing reply over the search results.
Until last week, that reply call was hardcoded to gpt-4o-mini. I wired a per-conversation model picker so the only thing that changes between runs is the model that turns retrieved data into Arabic prose. Router, profile extraction, negotiation rewriting, translated product summaries — all stay on gpt-4o-mini for fair comparison. Gemma is only writing the final reply. That hybrid-stack disclosure matters; it isn't doing the whole pipeline.







