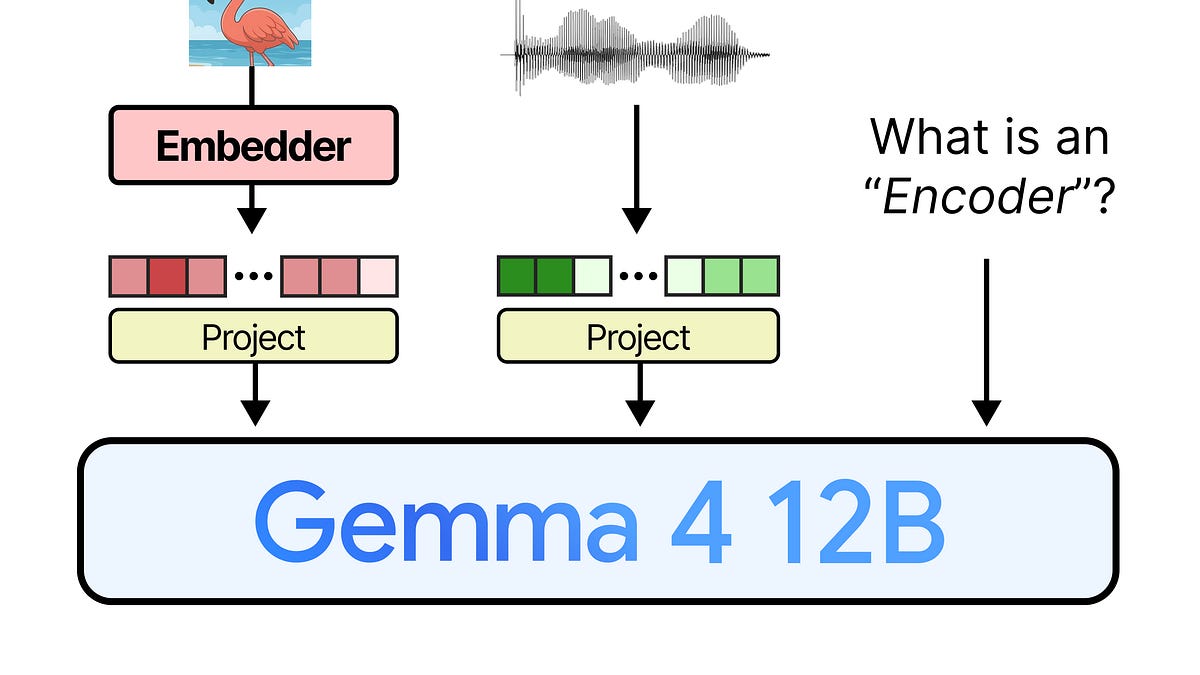
This is a submission for the Gemma 4 Challenge: Write About Gemma 4
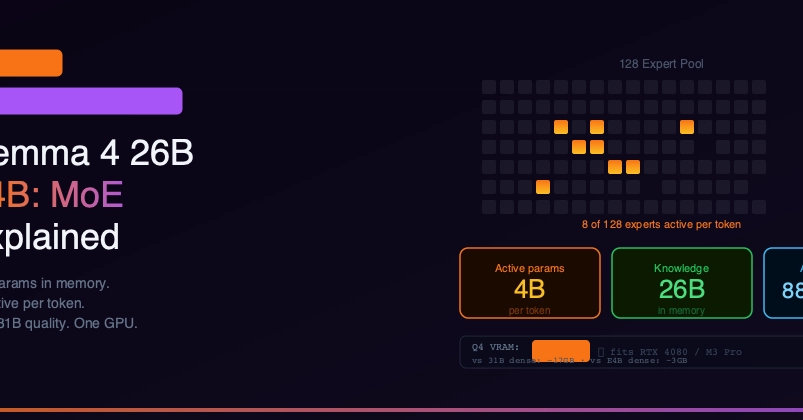
Gemma 4's most interesting model isn't the 31B flagship. It's the 26B A4B — a Mixture-of-Experts model that activates only 4 billion parameters per token while delivering performance nearly identical to the dense 31B.
If that sounds like magic, it's not. But the engineering behind it is worth understanding, because it changes what hardware you need to run a near-frontier model locally.
Dense vs MoE: The Core Difference
In a standard dense transformer (like Gemma 4 31B), every token that passes through the model activates every parameter. All 31 billion of them, every forward pass.