How to get Google's Gemma 4 26B-A4B Mixture-of-Experts model running locally — including speculative decoding — on hardware that has no business running it.
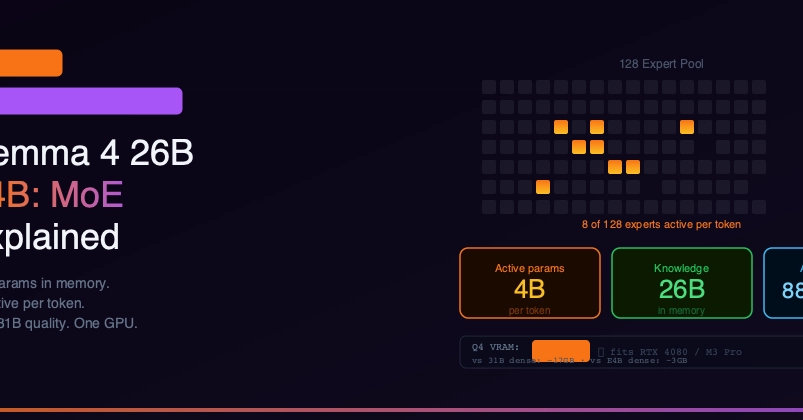
Google's Gemma 4 26B-A4B is a Mixture-of-Experts model: 25.2 billion total parameters, but only 3.8 billion are active per token. That distinction matters enormously for running it locally, because it means you can keep the cold expert weights in system RAM and stream them over PCIe, while a much smaller working set lives on the GPU.
This post walks through getting Gemma 4 running on a GeForce GTX 1080 — a 2016-vintage card with 8 GiB of VRAM — on Fedora 42, achieving ~24.5 tokens/second with 128k context, including fully-GPU-resident speculative decoding via Gemma 4's MTP assistant head.
For comparison: I also ran the Qwen 3.6 35B-A3B model through the same process. It produced slightly slower output at the same context length, and was much more verbose given the same prompts — so for typical assistant workloads, Gemma 4 ends up faster end-to-end regardless of tok/s.
The Hardware