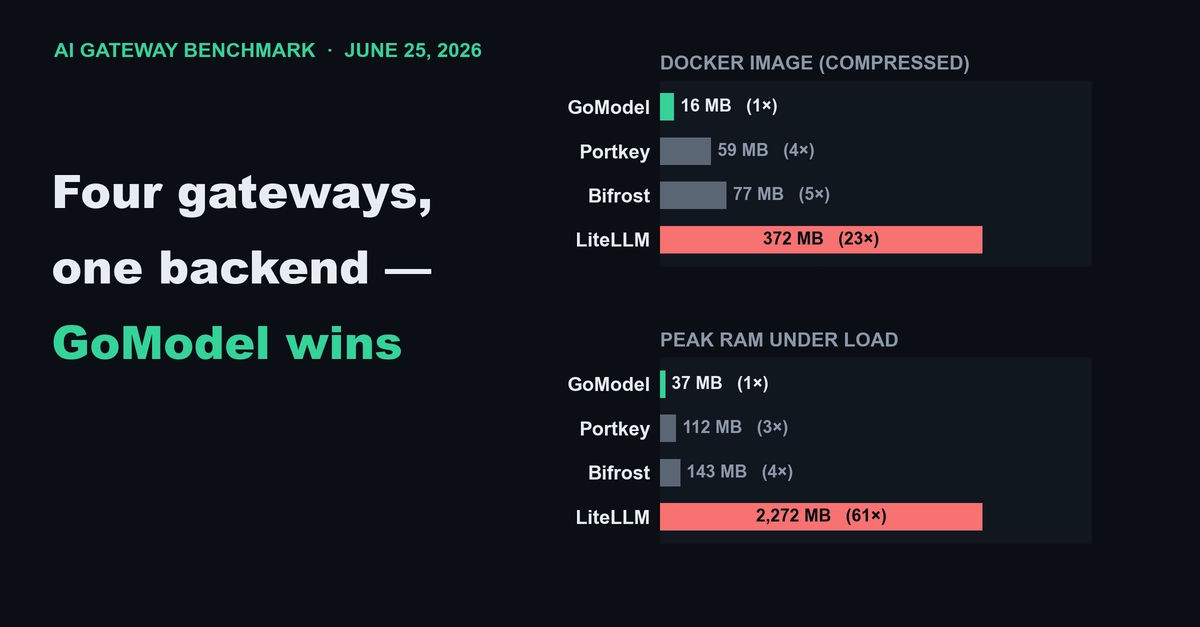
TL;DR: We measured failover latency across three AI gateways (Bifrost, LiteLLM, Portkey) during 30 days of production traffic at Nexus Labs. Bifrost added 11ms p99 overhead with automatic provider fallback. The model is the easy part. Routing it reliably is not.
Our agent platform at Nexus Labs handles around 2.4M LLM requests per day. Half of those hit OpenAI, the rest spread across Anthropic, Bedrock, and Vertex. When OpenAI had its 4-hour incident on April 23, we lost 38 minutes of traffic before our homegrown retry logic gave up and rerouted.
That hurt. So we replaced the retry layer.
The actual problem
Most gateway benchmarks measure throughput on a cold path with no failures. That tells you very little about production. What I care about: how long does it take for a request to recover when a provider returns 429 or 503? How much p99 latency does the gateway add when nothing is wrong?