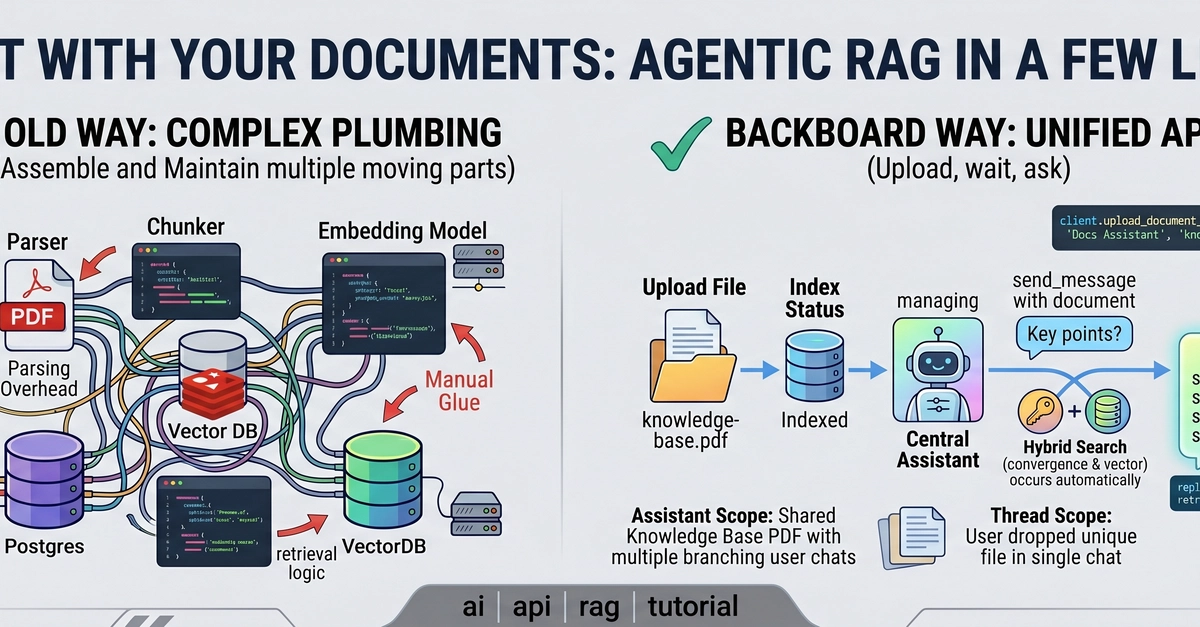
Most RAG tutorials start the same way: "First, install a vector database…" Then come the embedding models, the chunking strategies, the similarity thresholds. By the time you can ask a question about a PDF, you've deployed three services and written 200 lines of boilerplate.
Garudust Agent takes a different path. RAG is built in — backed by SQLite FTS5 with a trigram tokenizer. No vector database. No embedding API calls. Drop a PDF (or TXT, CSV, Markdown, JSON) into the conversation and start asking questions in seconds.
How It Works
When you ingest a document, Garudust:
Extracts text (native PDF parser, no external tools)