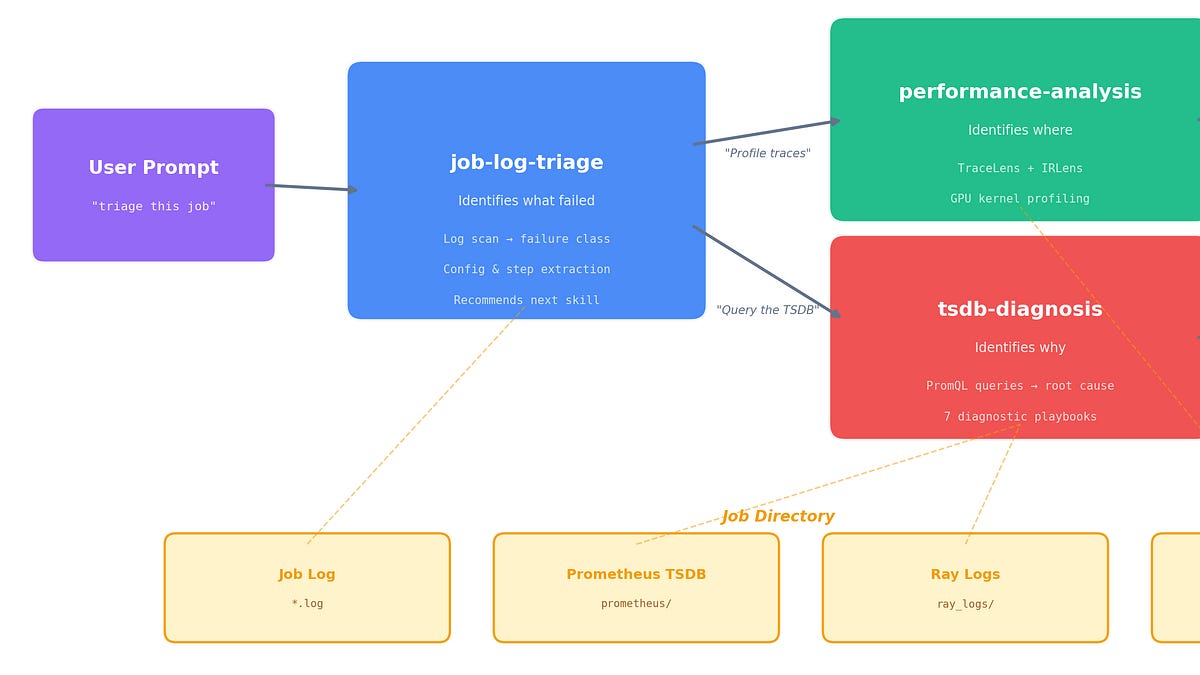
It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.Help me buy chocolate milkPS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6There’s an inflection point in training systems at scale where the hard problem changes shape. It stops being about whether you can get the job to run and becomes something more corrosive — figuring out why performance degraded, or why a failure signal appeared, or why throughput quietly cratered and nobody can explain it. That’s where the real cost lives. Not compute. Engineering hours burned reconstructing what went wrong from scattered dashboards and whatever the senior SRE remembers from last time.The following research from AMD was shared with me and I thought it was worth your time (goes without saying but this is not sponsored, I share only because I think you need to read it). So I’m sharing it with due permissions. It walks through the failure modes that actually eat people alive once clusters get big enough. This includes various issues likeNetwork degradation that looks like a training bug. False failure signals that trigger unnecessary restarts. Checkpoint-related slowdowns. Cases where everything looks broken but the root cause is in the training dynamics, not the infrastructure. Debugging large-scale training is moving from tribal knowledge and human pattern-matching toward diagnostic workflows that a system can actually execute. And the teams that figure out how to make that transition — how to turn their debugging knowledge into repeatable infrastructure instead of leaving it trapped in someone’s head — those are the teams that will compound their advantage over everyone else. This article will give you insight on the same. In MaxText-Slurm: Production-Grade LLM Training with Built-In Observability, we introduced MaxText-Slurm — an open-source launch system and observability stack for running MaxText LLM training on AMD Instinct GPU clusters. We showed how a unified Prometheus time-series database (TSDB) collects GPU, host, network, and training metrics into a single queryable store, persisted to disk so that no data is lost even if the job crashes.A unified TSDB is only as useful as the methodology applied to it. In this post, we show the agentic diagnostic skills that ship with MaxText-Slurm — structured runbooks that Cursor or Claude Code execute autonomously from symptom to root cause. This is not a chatbot answering questions about logs. The AI agent has tool access (shell, file system, HTTP queries to Prometheus) and follows each skill systematically: reading logs, querying metrics, interpreting results, and chaining steps until it reaches an actionable conclusion. We walk through five case studies — from one-prompt performance profiling to a throughput decline (measured in tokens per GPU per second, or TGS) whose root cause turned out to be model behavior — where each short prompt led to an actionable result in minutes.The AI agent needs access to two codebases: the maxtext-slurm repo (for skills, job outputs, and diagnostic tools) and the MaxText source (for code-level tracing during deep diagnosis). MaxText lives at /workspace/maxtext inside the training Docker image — a frozen snapshot baked into the container, not installed on the host. The most reliable setup is to run the agent inside the container on a cluster login node.SSH into a cluster login node and clone the repo onto a shared filesystem so that multi-node job outputs (logs, TSDB, profiles) are accessible from any node:ssh cluster-login-node
How to Diagnose Failures in Large AI Training Clusters
A practical look at how debugging workflows, metrics, and automated runbooks are used to investigate slowdowns and failures in large-scale model training.
3,845 words~17 min read