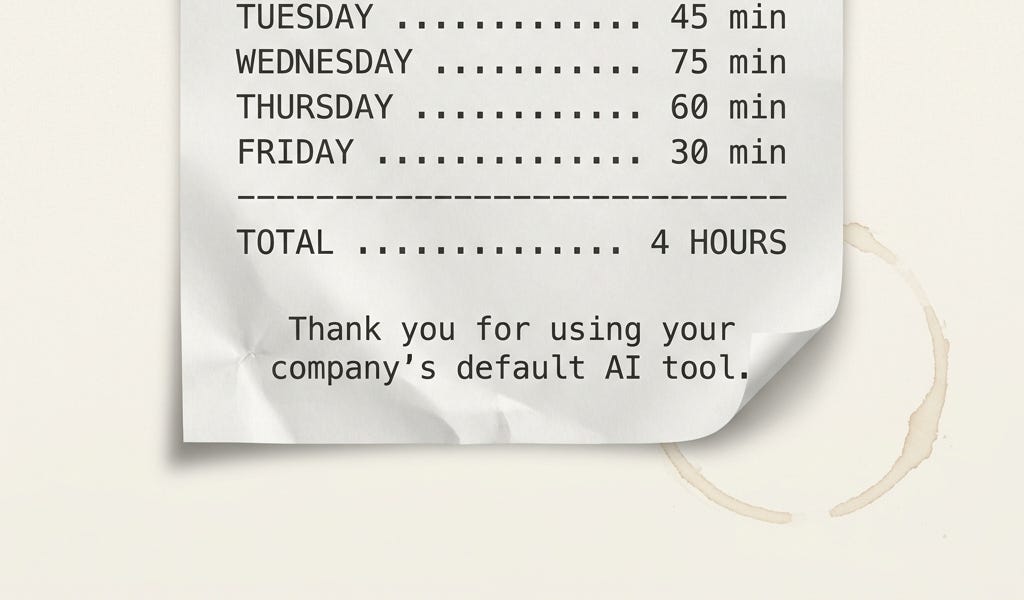
Your company’s default AI tool is bad at your job, you know it, your team knows it, and the moment you say so out loud you stop sounding like the person trying to get the work done and start sounding like the problem. That is the trap. If you are reading this and feeling a small tightening in your chest, it is warranted. Leadership wants frontier results. IT picked a default that cannot deliver them. You are stuck in the middle, paying the cost in thirty-minute chunks and five-minute corrections and the small flinch you feel every time the corporate assistant gives you something plausible and unusable. Every time you push back, it lands as taste.Preference, not performance.It lands as taste because that is the shape of the argument. “Copilot is bad” is not a thing IT can act on. Neither is “I need Claude.” Your IT organization has heard six versions of each from six different teams that all want a different product, and the only honest move available to them is to nod and do nothing. The argument that breaks through is different. It is specific, it is bounded, and it has a number attached to it. Almost nobody is producing that argument because nobody told them how.The thing that strikes me about Jaana Dogan’s post is how immediately she could judge what she was looking at. She is a principal engineer on Google’s Gemini API team. In January she posted that Claude Code reproduced in an hour what her team had spent a year building, and the post passed five million views in January alone. She recognized the delta the moment she saw it because she knew how to judge the output. You are the same kind of expert about the work you do every day. The unfiled ChatGPT Plus on your expense report and the Claude Code license your colleague is paying for personally are evidence, not embarrassment. The piece below is how you turn that evidence into something your company has to act on.Here’s what’s inside:Why your argument is bouncing. The shape of your case matters more than the strength of it, and almost nobody is making the right shape.The one-job, one-week test. Pick one job. Run it through both tools. Log four columns. The data is the argument.What the ask sounds like at three altitudes. Your manager wants one thing. Your CTO wants something completely different. Wrong altitude, wrong answer.If you are the one picking the default. The leader-side version, including the procurement model that skips the whole problem.Grab the prompts. Two prompts that turn this article into the actual moves: the Measurement Designer picks the right job and hands you the log; the Altitude Translator turns your log into three ready-to-send asks with objection responses pre-loaded.This is the third in a short series on the agent layer. The first was field notes on ChatGPT Workspace Agents. The second was the filter for deciding which agent launches matter. This one is the step most people skip. What to do inside a company that picked the wrong default and does not know it yet.
The four-hour-a-week tax you are paying because IT picked the wrong AI default
Watch now | What do to when your company's AI tool is bad at your job.
519 words~2 min read











