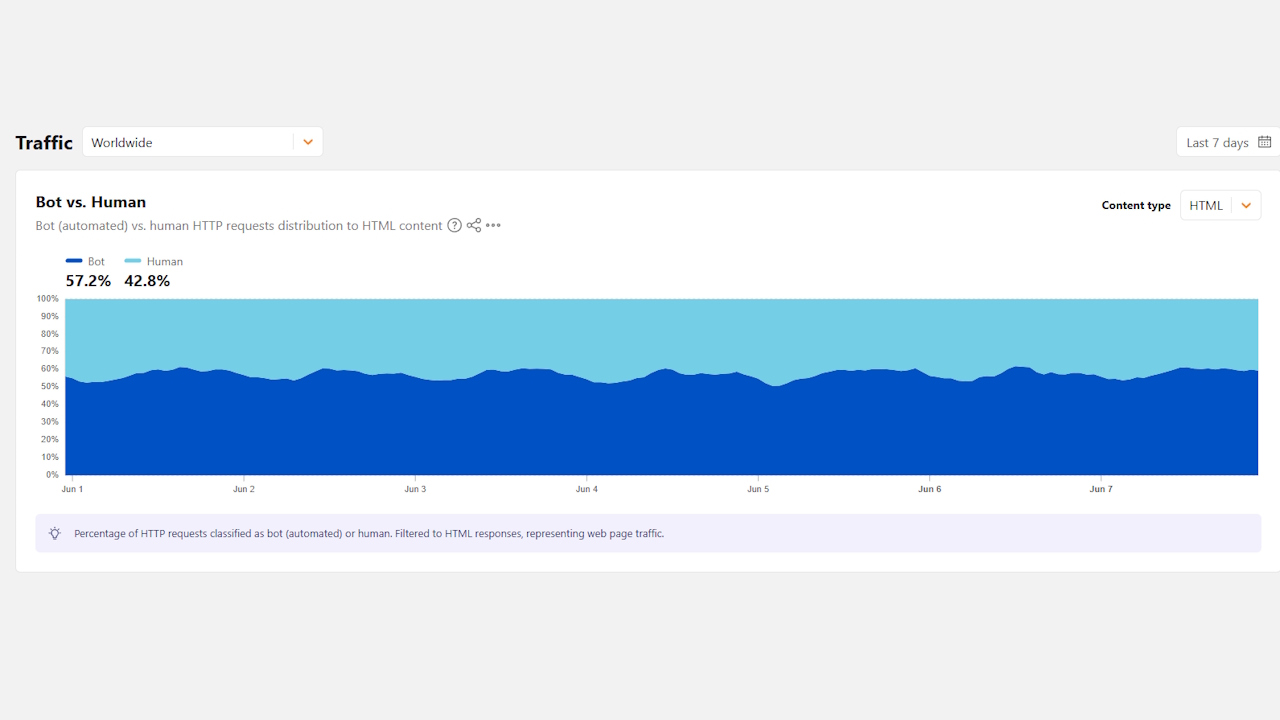
Si chiamano crawler AI e, con l’avvento dell’intelligenza artificiale, sono diventati il nemico numero uno di chi gestisce qualsiasi servizio online. Da quando è partita la competizione per lo sviluppo dell’AI generativa, il numero di bot che scansionano il web è aumentato esponenzialmente, al punto da mettere a rischio il funzionamento di molti servizi a causa del traffico che generano. Aziende del settore, sviluppatori e semplici appassionati si stano dando da fare per arginare in qualche modo il fenomeno, ma i tentativi per adesso non hanno dato grandi risultati. La trovata di una programmatrice canadese potrebbe riuscire a bloccarli, almeno per un po’.La “fame di dati” dell’intelligenza artificiale generativaPer migliorare le prestazioni dei loro modelli, gli sviluppatori continuano ad avere bisogno di addestrarli usando dati in quantità sempre maggiori e non esitano a saccheggiare Internet senza troppi riguardi. In particolare, utilizzando la tecnica dello scraping, cioè l’estrazione massiva di contenuti da siti di news, forum, repository documentali e qualsiasi altra possibile fonte rintracciabile in rete.Gli strumenti utilizzati sono bot che hanno due componenti: un crawler (che permette di navigare automaticamente tra le pagine web) e uno scraper, al quale è affidato il compito di estrarre i contenuti. Alle tante polemiche legate alle potenziali violazioni del copyright, su cui si stanno anche esprimendo i tribunali in mezzo mondo, si aggiungono quelle legate all’impatto che i bot hanno sulle infrastrutture informatiche che colpiscono.Ogni singola richiesta di un bot, infatti, impegna i sistemi ben più di quanto potrebbe fare un visitatore in carne e ossa. Il risultato è che le infrastrutture meno “attrezzate” rischiano di andare letteralmente in tilt. Ma anche le piattaforme più strutturate si trovano a dover fare i conti con un aumento di costi per gestire un volume di traffico che, per loro, non ha alcun ritorno economico.I tentativi di bloccare le “sanguisughe del web”Teoricamente, bloccare i bot che rastrellano dati per addestrare l’AI dovrebbe essere semplicissimo. Basterebbe inserire nelle pagine web un semplice file (robots.txt) che è in grado di comunicare con i bot e indicare quali parti di un sito web possono o non possono essere visitate. Il Robots Exclusion Protocol su cui si basa robots.txt esiste dal 1994 ed è stato pensato per limitare l’azione dei crawler usati dai motori di ricerca per indicizzare le pagine web. Ha però un limite: il rispetto delle regole inserite nel file non è in alcun modo garantito. In altre parole, quelle indicate sono delle “richieste” che il bot può tranquillamente ignorare.Anche selezionare quali bot possano accedere e quali no è terribilmente difficile. In teoria, i bot dovrebbero “dichiararsi” usando una stringa chiamata User-Agent, consentendo così al server web di individuare la tipologia di bot che si sta per collegare. La logica è semplice: usando una serie di filtri, è possibile consentire il collegamento ai bot “buoni” (per esempio il crawler di un motore di ricerca) e impedirlo a quelli dannosi, come gli scraper. Ancora una volta, però, si tratta di una sorta di regola non scritta, che è possibile ignorare senza alcuna conseguenza.A essere più rigorosi sono i cosiddetti captcha (Completely Automated Public Turing-test-to-tell Computers and Humans Apart), quei sistemi che prevedono un’interazione “umana” per accedere a un dominio, come la selezione di parti di immagini o altre attività simili. Le versioni più avanzate operano in maniera trasparente per l’utente, analizzando il suo comportamento (come il modo in cui viene mosso il mouse) per identificare i visitatori legittimi e quelli indesiderati. Col tempo, però, gli sviluppatori di bot hanno integrato nei loro software sistemi per aggirare anche queste tecniche.Quando il gioco si fa duroL’escalation nella lotta ai bot ha portato molte piattaforme a sviluppare sistemi estremamente evoluti, che sono in grado di analizzarli e selezionarli in base alle loro caratteristiche. Si tratta di servizi che hanno alle spalle un’attività di sviluppo, ricerca e addirittura di intelligence che ricorda molto da vicino quella delle aziende specializzate in cyber security. Anche qui, tutto sommato, si tratta di individuare dei software dannosi.Il livello dello scontro, però, non si ferma al rilevamento. Come fanno notare gli esperti del settore, il semplice blocco dei bot non risolve la situazione. Il rischio è che chi li gestisce si limiti ad aggiornarne o modificarne il comportamento fino a quando non saranno in grado di superare l’ostacolo.Cloudflare, attiva da tempo nel contrasto dei bot, ha recentemente sviluppato un sistema chiamato AI Labyrinth che mira a rendere la vita impossibile ai bot che fanno scraping dei contenuti. Quando uno di questi è stato individuato, viene automaticamente dirottato verso una serie di link che lo imprigionano in un circolo vizioso. Il bot, in pratica, finisce per “girare a vuoto” tra pagine web con contenuti posticci.Arriva AnubisUna soluzione decisamente più semplice è stata escogitata da Xe Iaso, una programmatrice e divulgatrice in ambito tecnologico che ha messo a punto un software in grado di distinguere tra un bot e un visitatore umano utilizzando un sistema che, almeno per il momento, si sta dimostrando estremamente efficace. Nel suo intervento al BSDCan tenutosi a Ottawa lo scorso giugno, Iaso ha spiegato che la decisione di sviluppare Anubis è arrivata quando un suo server è stato messo al tappeto dalle visite di un crawler di Amazon.La programmatrice non si è concentrata sull’idea di distinguere tra un software e un essere umano, ma ha adottato un altro approccio. Ha scelto di cercare un modo per distinguere tra un bot e un browser. Dopo qualche esperimento, ha infine trovato il modo di farlo. Il sistema è (relativamente) semplice: quando si prova ad accedere a un sito protetto da Anubis, viene richiesto di eseguire una serie di operazioni matematiche crittografiche tramite JavaScript. Qualcosa che i browser sono in grado di fare, ma i bot no.Anubis, pubblicato con licenza open source, ha ottenuto un immediato successo ed è stato implementato da numerosi enti e realtà del mondo tecnologico. Non solo: come sottolinea Iaso senza nascondere la sua soddisfazione, lo utilizza anche il sito dell’Unesco.
È sempre più difficile bloccare i bot che fanno scraping sul web per l'intelligenza artificiale
Le aziende che sviluppano modelli di AI generativa sono affamati di contenuti e li recuperano dal web usando software automatici, intasando i server. Ecco come sta andando la battaglia per bloccarli e l’ultima “arma” escogitata da chi li contrasta.
986 words~4 min read