Key Takeaways
You can't unit-test a coach agent the way you test a pure function — the output is non-deterministic and "good" is a judgment call, not an assertion.
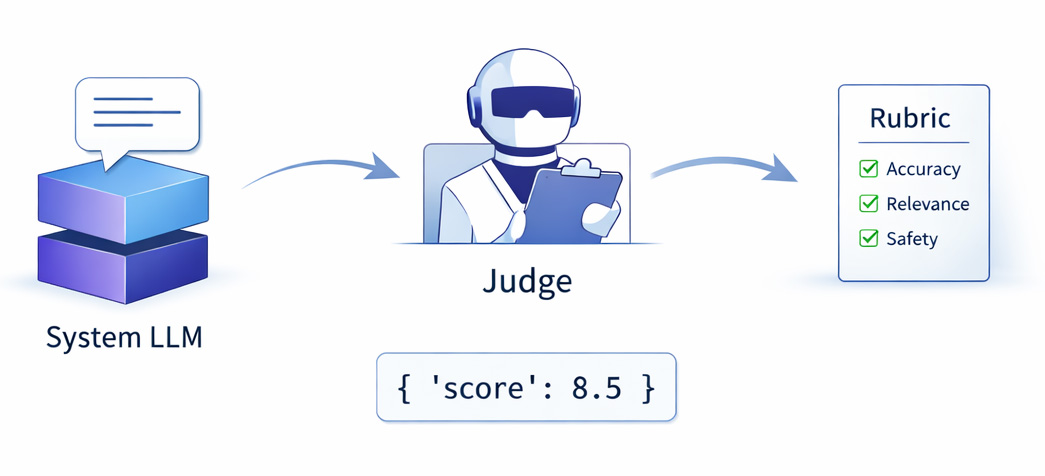
An LLM-as-judge harness lets you grade a whole test set automatically against a rubric, which is the only way solo-scale eval stays sustainable.
But the judge is itself a fallible model. If you don't design around its known biases — position, verbosity, self-preference, and quiet drift when the judge model updates — you build a green dashboard that means nothing.
The mitigations that actually work are mechanical, not prompt-magic: shuffle order on every pairwise call, pin the judge version, keep a small human-labelled anchor set, and re-check the judge against it.