Hey everyone 👋
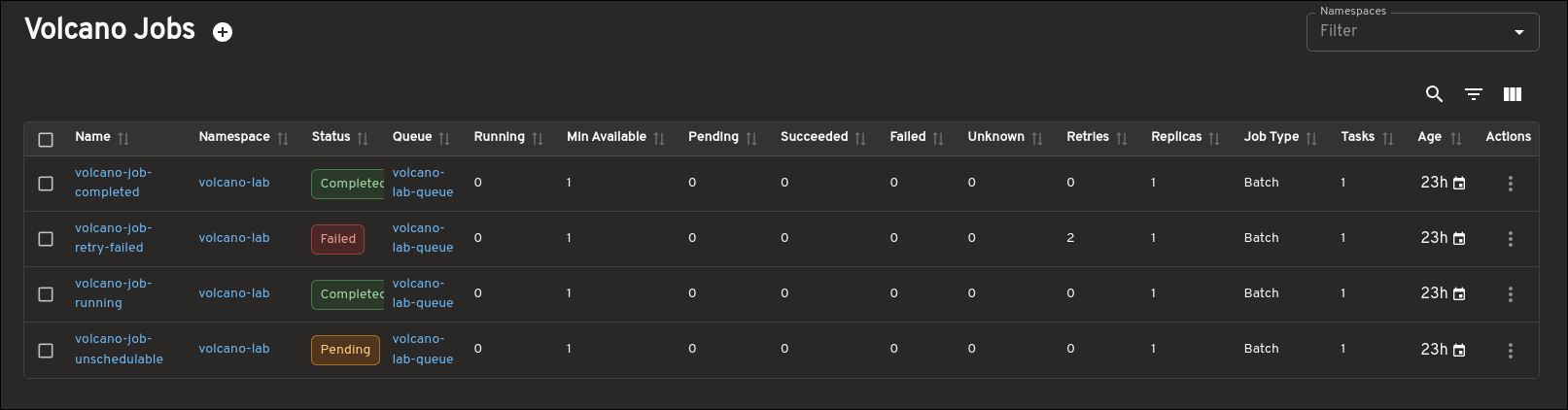
If you run batch jobs, data pipelines, or any kind of AI and ML training on Kubernetes, you have probably hit this wall. Kubernetes is fantastic at deciding WHERE a pod should run, but it is surprisingly clueless about WHEN a job should start. 😅
You submit ten jobs, the cluster fills up, and the rest just sit there as Pending. No real queue, no priority, no fairness between teams. One noisy team can eat all your expensive nodes while everyone else waits. 🥲
That is exactly the gap Kueue fills, and today I want to walk you through it with a pile of hands on examples you can run on any cluster, even your homelab. 🏡
Native Kubernetes scheduling is pod centric. The scheduler looks at one pod at a time and tries to place it. That works great for long running services.