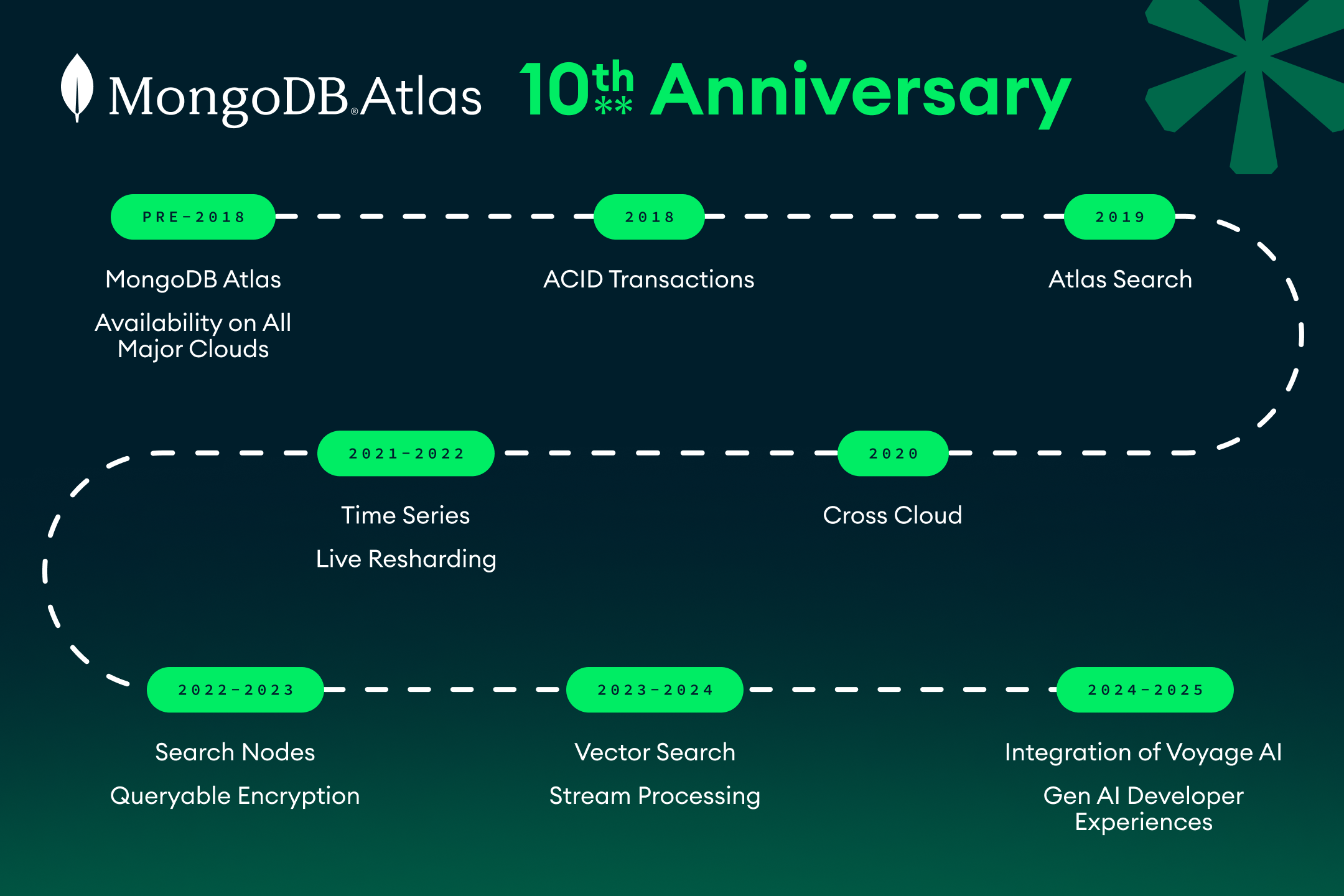
Many MongoDB journeys start with “Let’s just store it as JSON for now.”
Maybe it’s a product catalog with inconsistent attributes, data from multiple third-party systems that need to be mashed together, a rule engine whose rules change every sprint, or raw API payloads you just want to dump somewhere.
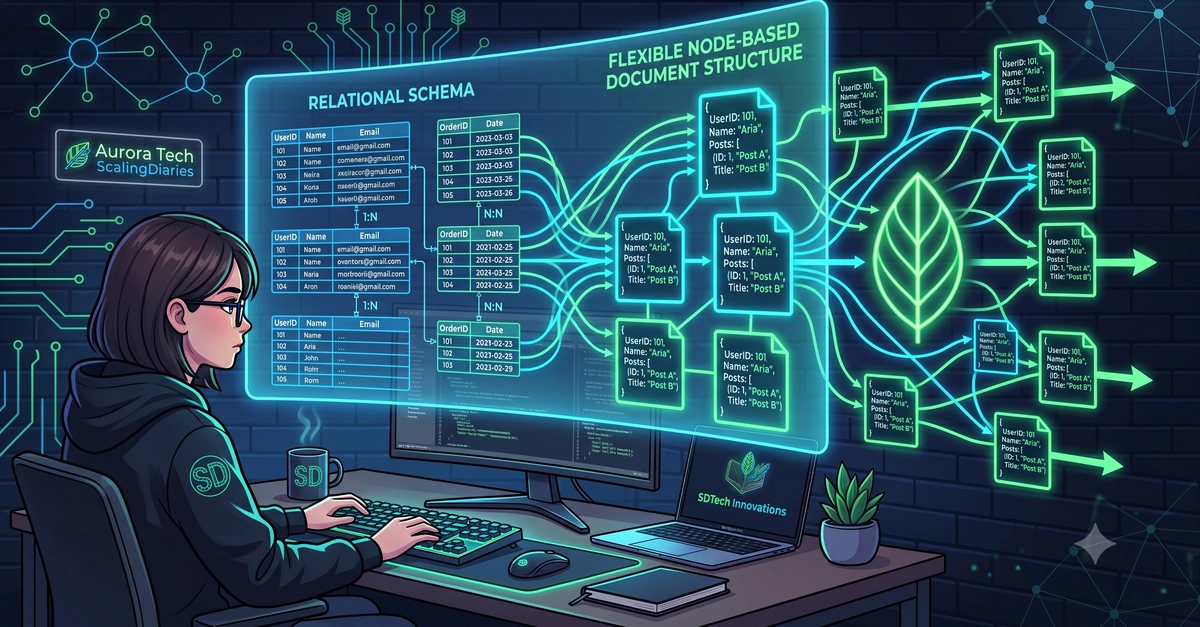
Then you realize that with a document model you don’t have to normalize everything.
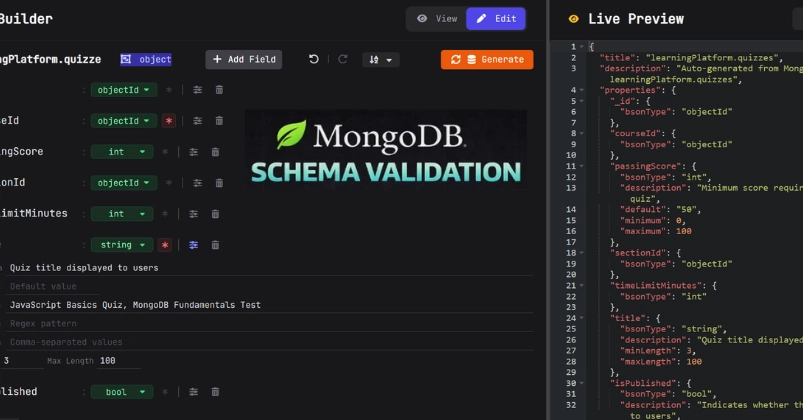
You start designing based on application usage patterns, embedding some entities together, keeping others separate and referencing them, applying some patterns like precomputed values or subset patterns, and enforcing schema validation…
Suddenly writes get simpler, reads need far fewer joins, and performance noticeably improves.