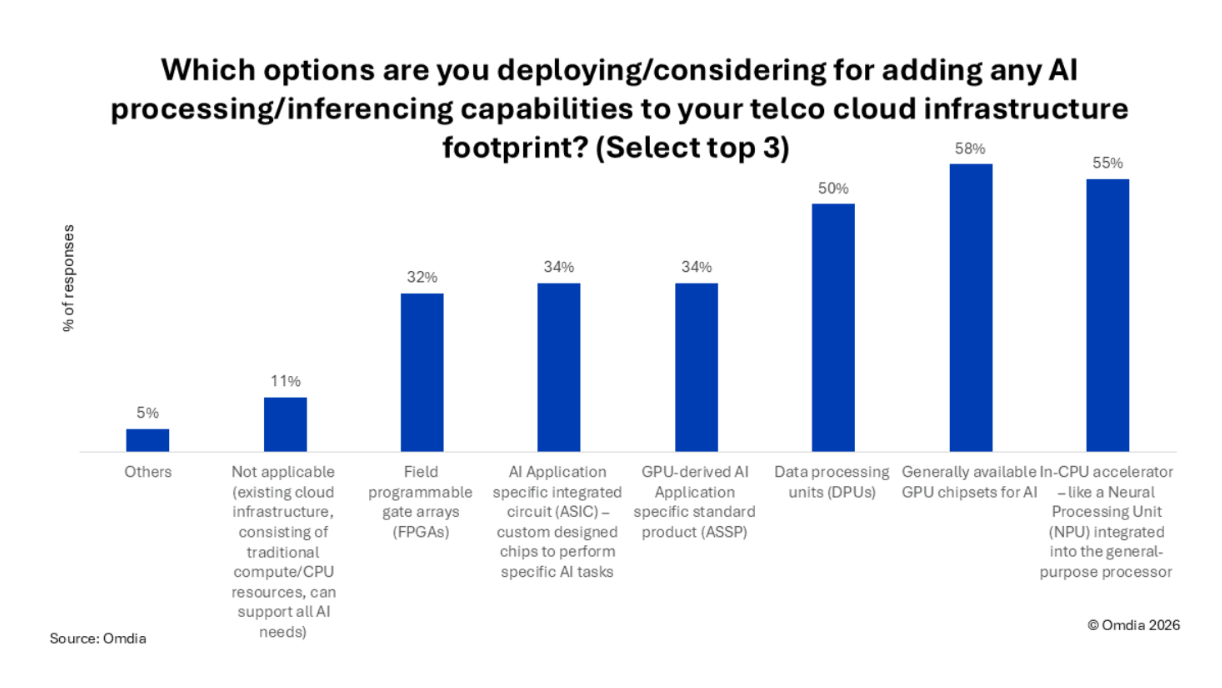
Every telecommunications service provider is operationalizing AI right now. Use cases include customer care-bots, network operation co-pilots, and managed AI-as-a-service (AIaaS) for external enterprise customers and others. The uncomfortable part is correlation of use case with business case, where the key factor is the cost of the AI accelerator, whether that's a graphics processing unit (GPU), tensor processing unit (TPU), or neural processing unit (NPU). Cost per inference decides whether these AI accelerators improve profit margins or erode them; to keep costs down, the AI model you select is as important as how you deploy that model and serve on a distributed geo-scale.In a recent article, Red Hatters worked on inference deployment challenges as an architecture problem shaped by traffic and scale, and not only by model size. This blog post summarizes their findings.How cost per inference affects profit and lossEach AI request has two distinct jobs inside, on the same hardware: First it reads the prompt/input, whether that’s a billing history, a trouble ticket, a network log, or something else that needs to be processed. Then it generates the response to that input, 1 token at a time.The reading phase decides how long the user waits for the first word; the writing phase decides whether the conversation feels fluid, or if it has frequent stops and starts. The two phases need different resource profiles and different optimizations, and when they share the AI accelerator resources, they compete.This tension affects profit and loss differently across different AI use cases and workload types. For instance, with customer care chatbots, care cost per contact rises when bots stall and sessions escalate to agents. Enterprise AI offerings accrue service-level agreement (SLA) penalties when they miss latency commitments. And margin on business-to-business (B2B) AI products erodes when the cost per query exceeds what the contract priced in. Most deployment mistakes are trade-off mistakes and arise when a team optimizes a metric that its product does not sell. Examining some specific ways in which AI generates revenue can illustrate the proper deployment for each workload type.Customer careCustomer care is the clearest case. Care traffic consists of thousands of short, simultaneous chat sessions that reuse the same tariff and policy preamble on every call. Red Hatters were able to identify the following from Red Hat’s vLLM benchmarks:Splitting and correctly sizing the read and write pools cut costs by 25-40% on this traffic shape.Cache-aware routing, the scheduling approach implemented by the open source llm-d project, delivered 2-3 times more tokens per GPU and 3-5 times lower cost per token where prompt reuse runs high.Production systems will not see this level of improvement, but the direction held across every workload we measured. At tens of millions of care interactions a month, reducing inference costs by even a few points can save enough money to pay for the next product cycle without new accelerator capital expenditure (CapEx).Network operationsNetwork operations are the opposite shape: there are few users, and the documents being processed are very long. Incident analysis rereads the same runbooks, topology records, and vendor manuals constantly, so the dominant cost lever is caching what has already been processed. The payoff is shorter time to diagnosis and fewer escalations to senior engineers.Managed AI sold to enterprisesSelling AI to enterprise customers adds a third shape: many tenants, tiered SLAs, and bursty demand. Two mechanisms can protect the margin in these scenarios:Model cascading sends routine queries to a small model and escalates only the hard ones, which cuts cluster costs by 40-60% where easy queries dominate.Admission control tied to service-level objectives (SLOs) rejects requests that would breach an SLA instead of queueing them into failure, which protects contract credibility under load.As shown in Table 1, together these 3 use cases can serve as the model for gold, silver, and bronze pricing tiers, rather than forcing customers to take a gamble on 1 shared AI accelerator pool. However, 2 more constraints round out the picture for service providers and illustrate ways AI services can be tailored for specific customers. Sovereign AI with cloudbursting capacitySovereignty rules require that subscriber data stay in its country of origin. The pattern that best meets that need is a regulated on-premise baseline with cloudbursting that stays cold between peaks. A single control plane such as Red Hat OpenShift AI keeps the two environments aligned so compliance does not depend on configuration discipline alone.Edge computingWhen considering the network edge, with roughly 100 concurrent sessions or less, the right answer is one model per accelerator with no clever pooling. Hard queries should be escalated over backhaul so transport spending tracks complexity rather than volume.WorkloadTraffic shapePrimary cost leverBusiness outcomeCustomer careThousands of short concurrent chatsHeavy prompt reuseSplit read and write poolsCache-aware routingLower cost per contained contactNetwork operationsFew usersVery long documentsCaching previously processed runbooks and recordsFaster diagnosisFewer senior escalationsManaged AI for enterprisesMany tenantsTiered SLAsBursts in demandModel cascadingSLO-based admission controlDefended marginPredictable tier economicsSovereign AI with burst capacityRegulated baselinePredictable peaksCloudbursting that stays cold between peaksCompliance without peak CapExEdge and field operationsFewer than approximately 100 sessions per siteCostly backhaul1 model per acceleratorEscalating only hard queriesOn-site resolutionBounded transport spendTable 1. How workload types lead to tangible business outcomesHere are the questions that providers need to ask when considering each of these use cases:Customer care: What does a fully automated care conversation cost today, and which single change moves that number the most? A good answer cites cost per contained contact measured on live traffic, with 1 tested lever and its before-and-after numbers.Network operations: How long does an engineer wait for a useful answer from incident records, and are the same documents being reprocessed every time? A good answer shows how often runbooks and site records are served from cache versus reread, and the trend in time to first answer.B2B services: Which enterprise SLA breaks first under peak load, and is the fix more hardware or better routing? A good answer names the breaking tier from a load test and shows that a routing or admission fix was tried before a purchase request.Sovereignty and peaks: How much capacity sits idle between peak events just to satisfy data-residency rules? A good answer reports baseline use and a burst design that costs nothing while it waits.Edge and field: What share of field queries travels back to a central cluster, and what does that transport cost? A good answer gives the local resolution rate per site, with escalation reserved for queries the on-site model cannot handle.Investment pathOnce an AI use case has been established, the next step is to build the use case in an efficient and cost-effective way. The sequence matters more than the destination. Each stage is triggered by a measurement, not a roadmap date, and each pays for itself before the next begins:Start with 1 node: Run a single serving instance on real care or network traffic for a week. That baseline is the measure for every later decision; synthetic lab traffic will be misleading.Add intelligent routing: A 2nd replica delivers less than 1.8 times the throughput of 1. That gap means requests are landing on servers that must reread context that another server already holds. It is routing waste, not missing capacity, so fix it before buying hardware.Separate the reading and writing pools: Do this only when measurement shows that 1 phase is starving the other by enough to cover the added operational complexity.Adopt the multitenant grid: When several products and B2B customers share the platform, the mechanisms that protect tiered SLAs earn their complexity. Below that scale they waste effort.Each step resets the baseline; AI inference strategy is a series of measured bets, not a one-time architecture sign-off. Service providers already run this playbook with wireless spectrum: allocate capacity to the products that have a return of investment (ROI) on it, measure continuously, and reclaim what sits idle. AI accelerators deserve the same discipline.ConclusionDistributed AI inference decides whether service provider AI products keep their margin. Nothing that has been outlined in this blog post asks for a bet-the-budget commitment: every mechanism is a measured step that proves itself on service provider traffic before the next-one starts, and Table 1 shows where to look first.When you are ready to work through this for your care, network, or B2B portfolio, bring your traffic data to your Red Hat account team. vLLM, llm-d, and Red Hat OpenShift AI are how we run this pattern with service providers today, and the conversation moves fastest when it starts from your needs, not from a generic blueprint.
Distributed AI inference: What telecom service provider leaders should know
Learn how Red Hat OpenShift AI can help service providers optimize their AI inference costs and improve profit margins for various AI use cases.
1,406 words~6 min read