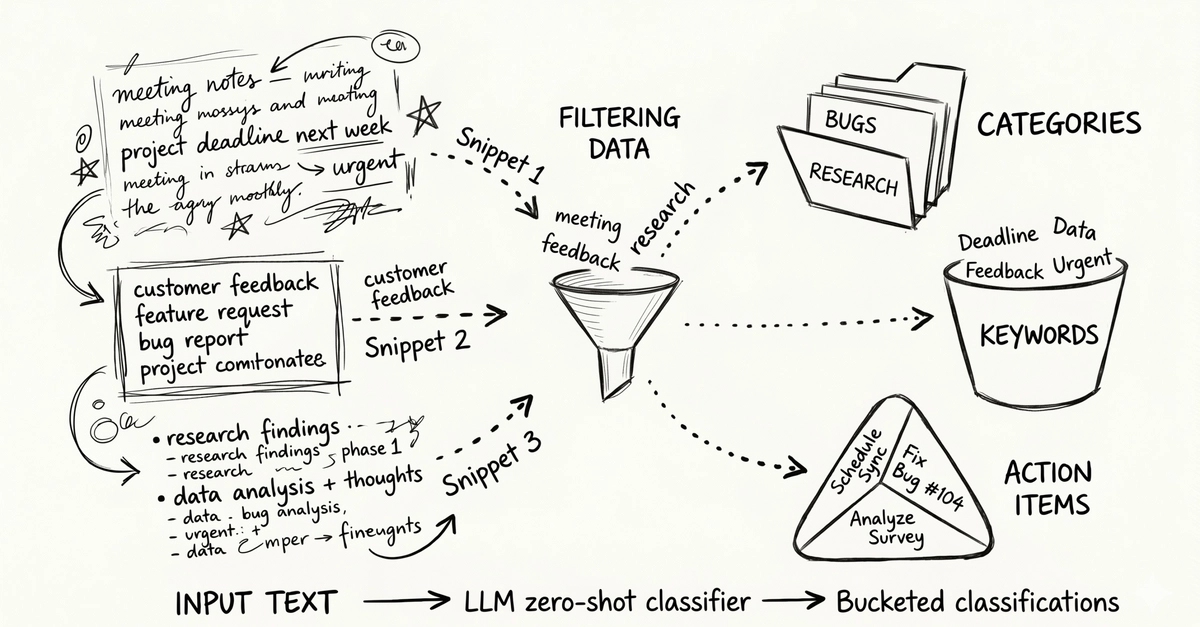
The problem
A cost efficient AI system sends easy work to a cheap model and only escalates hard work to an expensive frontier model. The trouble is knowing which is which. When a task has a test, like code with unit tests, you just run the test: if the cheap answer passes, serve it; if not, escalate. But most real prompts have no test. A question like "what time is the maintenance window" cannot be checked by running code. With no test, a careful system escalates almost everything, and you pay frontier prices for work a cheap model could have done.
We measured our own gateway and found exactly that. On no-test prompts in automatic mode, the system escalated to the frontier 100 percent of the time, at every context length. The cheap tier was capable, but the system did not trust it without a test, so it never served those answers.
The idea: agreement as a stand-in for a test
Instead of a test, ask a second, independent cheap model the same question. If the two cheap models agree, the answer is very likely correct, so serve it cheap. If they disagree, that is the genuinely hard case, so escalate to the frontier. Disagreement never serves a worse answer than before, because the disagreement path is the same escalation that used to happen anyway. Agreement only adds a chance to skip an unnecessary frontier call. The gate is conservative by construction, so its only failure mode is paying for an avoidable escalation, never serving a wrong answer, unless the two cheap models happen to agree on the same wrong answer. That single risk is the whole ballgame, so we measured it directly.