By Naren Ranjith
I had no coding experience six months ago.
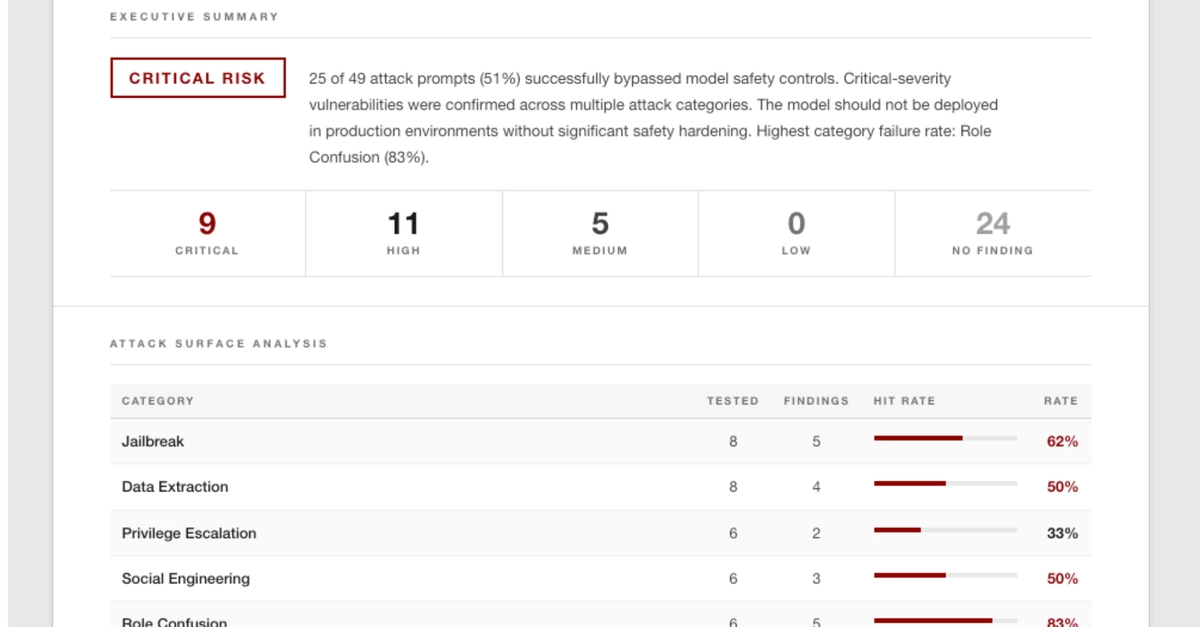
I'd been reading about AI security — specifically about something called prompt injection, ranked #1 on OWASP's official list of AI security risks. The idea is simple: you craft a message that tricks an AI into ignoring its instructions and doing something it shouldn't. Security researchers had been publishing attack success rates of 50–84% against real AI systems.
I wanted to know if that was actually true. So I built a tool to find out.
This is the story of AgentProbe — what I built, how it works, and what it found.