Six weeks ago I shipped Lunaris Guard v0.1 — a dual-head classifier for prompt injection and content safety. On paper, it looked decent: 0.74 F1 on injection, multilingual coverage, Apache 2.0.
Then I tested it on something that wasn't in the training data.
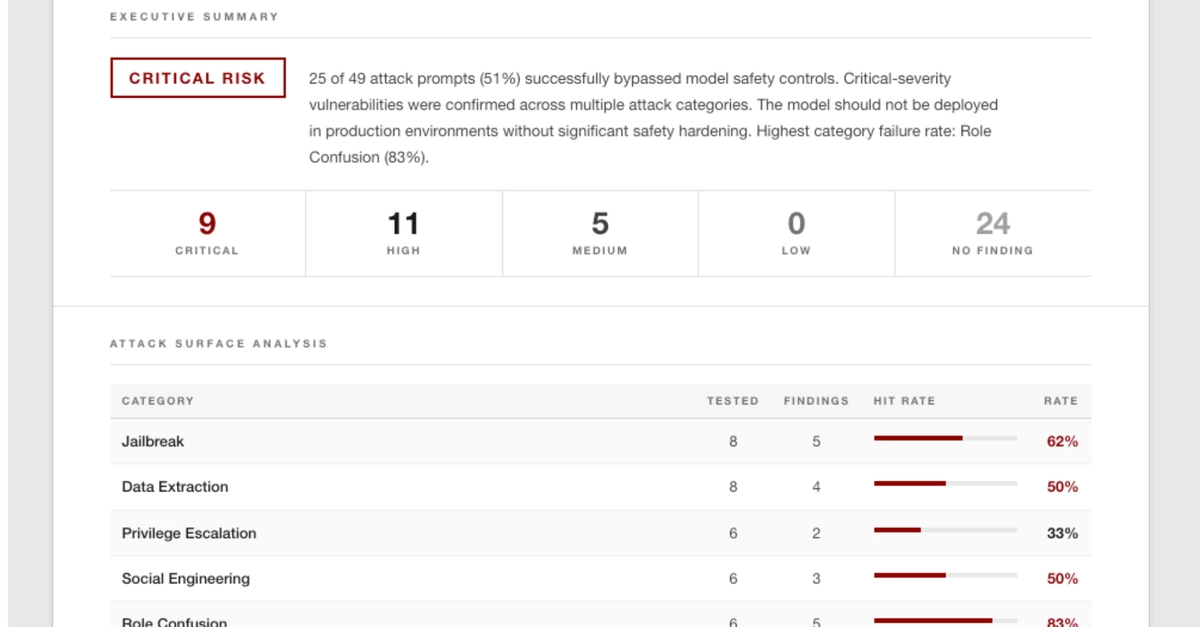
It failed. 63% of the time.
That number — 37% recall on novel attacks — meant v0.1 was useless in production. Attackers don't send you prompts from your training set. They send you things you've never seen.
So I burned the v0.1 weights and started over.