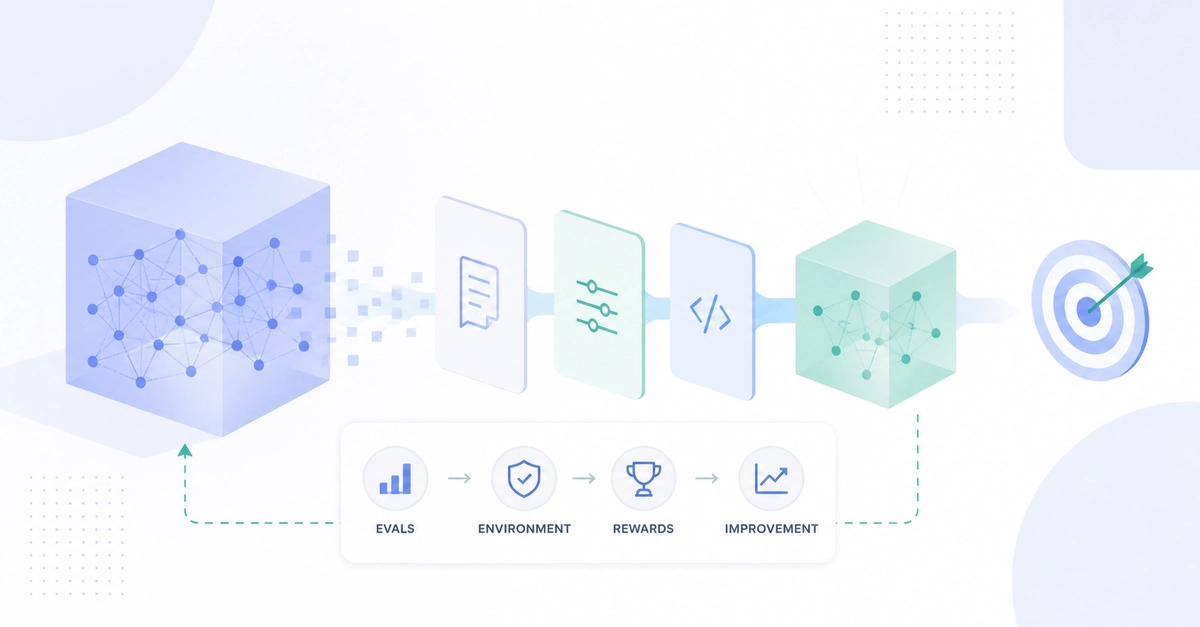
Fine-tuning an LLM means taking a general pre-trained model and training it further on your own data so it gets good at exactly what you need. In this guide, you will get a practical, step-by-step walkthrough covering every stage from dataset prep to deployment, written for engineers and developers who want to get things done.
If you have been wondering whether to fine-tune or just keep prompting, you are in the right place. Let's get into it.
What Is LLM Fine-Tuning and Why It Matters?
LLM fine-tuning is the process of taking a pre-trained language model and continuing its training on a smaller, task-specific dataset. It is one of the most effective ways to make a general-purpose model actually useful for your specific problem.
Think of it this way. A pre-trained language model is like a brilliant generalist who has read most of the internet. They are great at conversation, reasoning, and writing. But if you need someone who talks like a cardiologist or responds like your brand's support agent, you need to train them further. That is exactly what fine-tuning does.