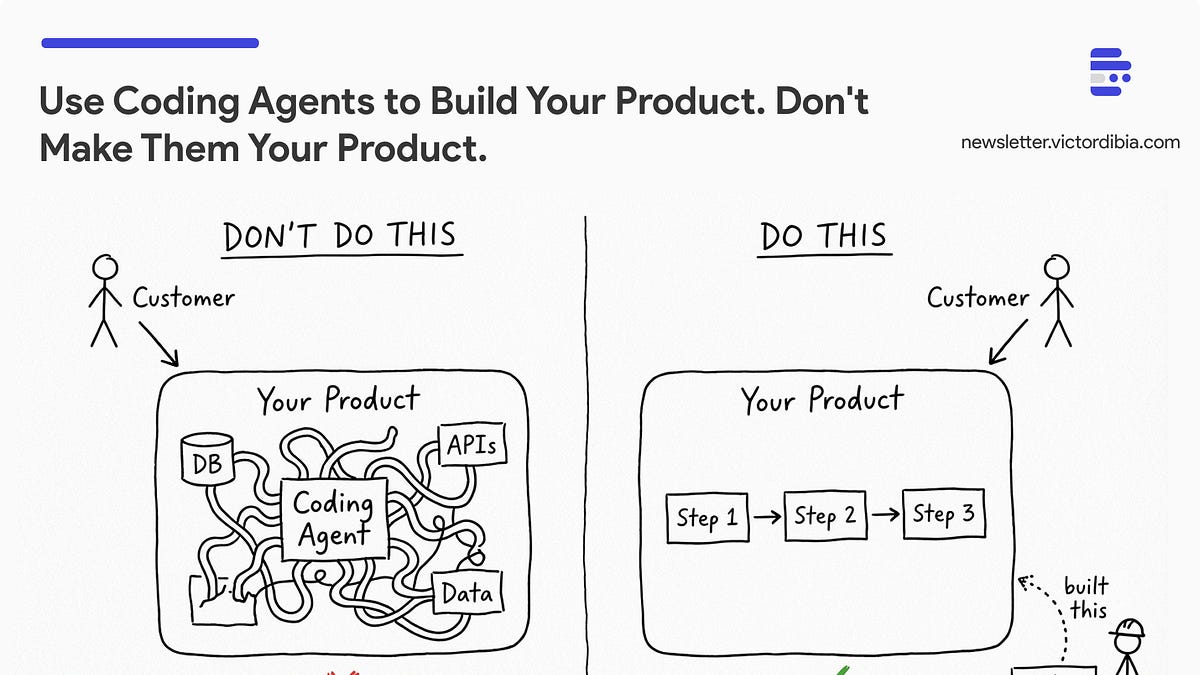
Coding agents can produce working UI fast, but what's harder is a different shape. They can copy your product's style, match its patterns, and try to follow its conventions. What they cannot do is understand why those patterns exist. Code shows agents what shipped, not why one component, phrase, or interaction became your standard. That reasoning lives in design reviews, PR comments, Slack threads, and with the people who were in the room. For an agent, context that isn't in the codebase doesn't exist.Vercel is an agent-native team. We treat accepted product decisions like code, keeping them in the repository, reviewing changes against them, and making them available to every agent working there.The way we do this is through product-design. It's a system with three parts:An agent skill that gives coding agents the context behind decisions that require product or codebase judgment.Linters that enforce clear rules automatically.A review loop that gathers evidence from Slack, Figma, and GitHub, then prepares guideline updates for review.Any team can build the same structure around their own standards.Link to headingInside the product-design skillThe skill lives inside the repository alongside the code it governs. Here's a simplified view of its structure:repository/├── AGENTS.md├── .agents/│ └── skills/│ └── product-design/│ ├── AGENTS.md│ ├── SKILL.md│ ├── references/│ │ ├── product-judgment.md│ │ ├── interface-quality.md│ │ ├── resilience.md│ │ ├── surfaces.md│ │ ├── surfaces-{surface}.md│ │ ├── copy.md│ │ ├── rules.md│ │ ├── glossary.md│ │ ├── patterns.md│ │ └── coverage-gaps.md│ └── exemplars/│ └── pr-{name}.md└── tooling/ └── scripts/ └── copywriting-eval/ ├── fixtures.json ├── rules-checklist.json └── <fixture>/ ├── before/ └── after/The product-design skill structure inside the repository.The repository AGENTS.md tells coding agents when to load the skill. The skill-local AGENTS.md defines load order, validation, and governance. SKILL.md owns the runtime workflow.references/ stores product-judgment, interface-quality, resilience, copy, canonical product names, interaction patterns, and surface-specific decisions.exemplars/ documents decisions worth repeating from shipped pull requests, along with mistakes to avoid. coverage-gaps.md lists areas where we do not have a standard yet.copywriting-eval/ tests copy and interface-language behavior. It does not evaluate the broader product-design workflow.Link to headingHow the skill routesSKILL.md resolves the request mode first: shape, implement, review, copy, or harden. This keeps audits from becoming edits and copy passes from expanding into redesigns. It skips backend-only work, telemetry, console errors, generated files, and tests with no shipped UI impact.The skill routes to canonical sources instead of duplicating them. Component APIs, design-system rules, accessibility criteria, and interaction guidance stay with their owners.Routing is specific to both task and surface. Material changes load product-judgment and interface-quality first. Copy, component, layout, interaction, accessibility, and resilience work each route to focused references. A modal loads destructive-action patterns and canonical verbs. A settings form loads labels, validation, progressive disclosure, and accessible-name guidance.You can use this simplified structure as a starting point and replace the paths and standards with your own:SKILL.md---name: product-designdescription: >- Single entry point for product design and user-facing product implementation in apps/vercel-site. Use whenever work changes what a user sees, understands, chooses, or does: shaping requirements and flows; building or redesigning pages and components; reviewing URLs, screenshots, diffs, or Vercel Agent findings; improving product copy, information architecture, component choice, Geist compliance, hierarchy, layout, interaction, accessibility, responsive behavior, and loading, empty, error, permission, billing, or destructive states. Trigger on design, UX, UI, usability, flow, onboarding, settings, dashboard, build, improve, fix, audit, review, polish, simplify, or production-ready requests. Also use when backend behavior changes a user-visible outcome. Not for backend-only work with no user-visible effect, tests with no shipped UI impact, telemetry-only work, documentation, or marketing content.---# Vercel Product DesignMake the interface correct for the user, the product, and Vercel. Working code is not enough: choose the right interaction, make scope and consequences clear, cover reality beyond the happy path, and verify the rendered result.## Operating Contract- **Start with the job, not the pixels.** Identify who is acting, what they are trying to accomplish, the product object involved, and what the system will change.- **Define the outcome before the output.** Establish the current user problem, desired behavior, success signal, and non-goals before choosing a surface or component.- **Use evidence, not taste.** Trace decisions to product behavior, canonical repository guidance, an accepted design decision, or a verified adjacent pattern.- **Separate facts from decisions.** Mark assumptions and unresolved product choices explicitly; do not hide them inside implementation details.- **Treat shipped code as evidence, not automatic precedent.** It proves what exists, not why it is correct. Check it against current components, product behavior, and explicit guidance.- **Choose the smallest coherent intervention.** Consider better defaults, behavior, or reuse before adding UI. Do not solve one job by creating unrelated settings or abstractions.- **Decide before decorating.** Resolve information architecture, component semantics, interaction, and state behavior before styling or rewriting copy.- **Design every reachable state.** Include only states the product can actually enter, but do not stop at the populated success case.- **Verify the real surface.** Source inspection establishes behavior; a rendered interface establishes visual and interaction quality. Never claim visual verification from code alone.- **Keep one user-facing entry point.** Invoke `product-design`; route internally to the canonical sources below.## Request ModesResolve the mode from the user's verb and artifact before acting.| Mode | Typical request | Required behavior || --------- | ---------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------- || Shape | "Design this flow", "How should this work?", feature brief without settled UI | Frame the problem and evidence, compare material alternatives, then define the flow, states, acceptance criteria, risks, and open decisions. Do not edit unless asked. || Implement | "Build", "fix", "improve", "make compliant", or "run product-design on everything" | Resolve material product decisions, then implement the smallest coherent end-to-end change within scope. Do not absorb unrelated review findings. || Review | "Audit", "critique", "what's wrong?", code review | Inspect source and rendered evidence, then report prioritized findings. Do not edit unless asked. || Copy | "Fix the copy", "rewrite these errors" | Edit user-facing language, accessible names, and directly required JSX only. Report structural blockers without silently broadening scope. || Harden | "Polish", "production-ready", "handle edge cases" | Preserve the settled product direction while fixing state, resilience, responsive, accessibility, and finish defects. |When intent is ambiguous, use the narrowest mode supported by the verb. A URL, screenshot, route, or component identifies scope; it does not by itself authorize edits.A material decision changes the user's task, default, scope, consequence, navigation, interaction surface, or reachable states. Copy mechanics, token replacement, and established component substitutions usually are not material.## Decision AuthorityResolve conflicts in this order:1. The user's explicit goal and constraints.2. Verified user/product evidence and system truth.3. Repository-canonical guidance: `AGENTS.md`, Geist component APIs, `packages/geist/STYLE_GUIDE.md`, and routed skills.4. Accepted product/design decisions and exemplars with stable evidence.5. Verified adjacent shipped patterns in the same product area.6. General interface heuristics.## Workflow### 1. Set scope and modeName the target surface and request mode in the work plan or review notes.### 2. Load product contextBefore proposing UI, read the applicable `AGENTS.md` chain, supplied briefs and designs, and the product logic that determines mutations, permissions, validation, errors, and side effects.### 3. Model the product decisionFor Shape, Implement, Harden, full Review, or any material product/flow change, read `product-judgment.md` and write a compact internal brief covering user, job, current behavior, desired outcome, success signal, non-goals, object, scope, action, consequence, reversibility, permissions, and open decisions.### 4. Map the surface and statesInventory entry points, visible regions, overlays, transitions, exits, and return paths. Map only reachable states including loading, empty, sparse, populated, validation, error, permission, disabled, optimistic, stale, destructive, and responsive variants.### 5. Load the routed references| Need | Load || ---- | ---- || Product/flow/component decision | `product-judgment.md` + `component-guide` || Implementation, material visual change, or full review | `interface-quality.md` || Copy or accessible names | `copy.md` + `surfaces.md` routing || Layout, typography, color, spacing, Geist APIs | `design-guidelines` + `packages/geist/STYLE_GUIDE.md` || Keyboard, focus, forms, touch, animation, URL state, performance | `web-interface-guidelines` || Overflow, localization, extreme data, network/error resilience | `resilience.md` |### 6. Decide, then implementFor each non-mechanical change, be able to answer: what user problem does this solve, why is this component appropriate, what consequence must the interface communicate, which evidence supports the decision, and what is the smallest coherent change?### 7. Verify1. Confirm the primary job and acceptance criteria.2. Run repository lint checks.3. Inspect relevant compact and wide viewports.4. Exercise every materially changed reachable state.5. Verify keyboard order, focus movement, loading behavior, and pointer/touch targets.6. Test long content, large values, constrained width, and localization/RTL risk.7. Load `review-design-system` for structural visible changes.## Product Design Standards- Make the user's primary task and primary action unmistakable.- Preserve the user's mental model and current context unless changing it solves a verified problem.- Name the exact object, scope, and consequence of important actions.- Use navigation components for navigation and action components for actions.- Choose surface persistence to match importance.- Prefer inline disclosure before adding a modal.- Expose advanced controls when needed without making the default path carry their complexity.- Prefer strong defaults and direct behavior over adding configuration the user must learn and maintain.- Use semantic Geist components and their APIs before custom HTML or styling.- Use hierarchy, spacing, and alignment before adding containers.- Preserve user input through validation and recoverable errors.- Keep loading control labels stable; use the component's loading/busy affordance.- Make destructive actions proportional to impact and provide undo when the system can honestly support it.- Do not add decorative novelty, motion, or copy unless it clarifies structure, state, or brand intent.## Review OutputLead with findings, ordered by user impact:- **P0:** blocks the primary task, creates severe accessibility failure, or can cause unrecoverable user harm.- **P1:** likely task failure, misleading consequence, missing critical state, or major responsive/accessibility defect.- **P2:** meaningful friction, inconsistency, weak hierarchy, or recoverability issue.- **P3:** minor craft or consistency improvement.For each finding include: file/line or rendered location, verification status, canonical source, user consequence, and smallest concrete fix.## Skill Integrity- Add or change a rule only after current-source verification and human acceptance.- Record scope, rationale, evidence, exceptions, and a bad/good example.- Prefer the narrowest destination: canonical source, routed reference, exemplar, lint/eval check, or coverage gap.- Keep deterministic checks mechanical. Keep judgment in prose with its evidence and degree of freedom.- Never promote one screenshot, one shipped file, or one reviewer comment into a universal rule by itself.The product-design SKILL.md. Routing modes, operating contract, and governance.Routing is only part of what makes the skill useful. The other part is how findings stay traceable once the skill produces them.Link to headingMake findings traceableCopy rules have stable IDs and point to their canonical sources:rule/destructive-names-actionSource: copy.md > Actionable; verbs.mdRule: Destructive CTAs follow Verb + Noun. Never use Confirm, OK, or a bare verb.Example rule format with stable ID and canonical source.When Vercel Agent proposes a patch, it validates the change in a secure Vercel Sandbox with the repository's builds, tests, and linters before posting the suggestion.Link to headingUse linters for faster feedbackWe prefer deterministic checks when a linter can enforce a rule reliably. Linters are fast and cheap to run, so developers and coding agents get feedback while they work instead of waiting for a later review.Code can count two or three static options, so a linter can recommend radio buttons. Naming the right object and consequence for a destructive action requires product context, so the skill handles it.Examples in the codebase include rules that:Prevent nested modals, which break focus management, keyboard navigation, and layering.Recommend radio buttons instead of a select for two or three static options, so every choice stays visible.Require accessible names for icon buttons and form controls, and reject custom focus rings that bypass shared focus tokens.Prevent className from overriding a design-system component's color, radius, or shadow while still allowing layout classes.Require Modal.Body so long content scrolls correctly and headers and footers can remain sticky.Replace raw shadows with theme-aware Material classes and reject borders that duplicate a Material's built-in treatment.Flag arbitrary spacing that falls off the 4px grid and suggest a standard utility when one exists.Each rule explains why the pattern is a problem and suggests a concrete fix. Some rules autofix safe migrations, such as replacing deprecated Tailwind utility names.Accepted decisions can take several forms:Human-readable guidance next to the relevant Geist component, such as Checkbox best practices.Agent guidance in the product-design skill.A lint rule when code can check it reliably.The lint rule below shows how one product guideline is encoded as a deterministic check:prefer-radio-for-few-static-options.js/** @type {import('eslint').Rule.RuleModule} */module.exports = { meta: { type: 'suggestion', docs: { description: 'Suggest Radio buttons when Select has 2-3 static options', category: 'Design System', recommended: true, }, schema: [], messages: { preferRadio: 'Select with {{ count }} static options. Consider using Radio buttons — they show all options at once without requiring a click to open.', }, }, create(context) { return { JSXElement(node) { const opening = node.openingElement; if (opening.name.type !== 'JSXIdentifier') return; if (opening.name.name !== 'Select') return; const hasDynamic = node.children.some( (child) => child.type === 'JSXExpressionContainer' && child.expression.type === 'CallExpression', ); if (hasDynamic) return; const optionChildren = node.children.filter( (child) => child.type === 'JSXElement' && child.openingElement.name.type === 'JSXIdentifier' && child.openingElement.name.name === 'option', ); if (optionChildren.length < 2 || optionChildren.length > 3) return; context.report({ node: opening, messageId: 'preferRadio', data: { count: String(optionChildren.length) }, }); }, }; },};Lint rule that recommends radio buttons over selects with 2 or 3 static options.Each of these catches a class of mistake automatically, freeing code review for the decisions that actually require judgment.Link to headingHow we test the guidance with evalsLint rules are deterministic, but agent behavior can vary, so we test the skill on interfaces it has not seen before.An agent edits a before state, then a judge checks the results against a rubric.Evals come from shipped examples documented in the skill. Holdouts hide their expected edits, testing whether the guidance generalizes. We also run fixtures without the skill to measure whether it changed the agent's behavior.We score rule correctness separately from similarity to the shipped result. Shipped code can contain a flaw that the agent should improve instead of reproduce.Link to headingKeep the guidance currentProduct standards change as components, names, workflows, and failure states change, and every update needs evidence and human review.Our weekly evidence-intake workflow collects design feedback that may improve product-design. It searches Slack conversations and preserves links to Figma files, pull requests, review comments, and previews as evidence. When evidence is incomplete, it records the code or commit needed for verification.The workflow separates collection from judgment:A collector gathers messages, links, and nearby context without proposing rules.A separate judge groups the evidence, verifies sources, and records open questions.The job creates a review packet with candidates, rejected topics, follow-up requests, and coverage gaps.Every candidate links to its source and remains pending. A comment from an experienced reviewer can raise its priority, but every candidate still needs evidence.Automation ends with the review packet. A human decides whether a candidate becomes agent guidance, a lint rule, an example, an eval, or no change. Accepted changes go into the narrowest relevant file and pass the relevant checks before merging.Link to headingHow to build product-design into your codebaseOur setup reflects Vercel's product, components, and review history, but other teams can adapt the structure to their own standards.Link to heading1. Start with repeated decisionsChoose one product surface where the same review comments keep appearing: destructive actions, error states, settings forms, empty states, or navigation. Collect examples from shipped code and real reviews, and write down the decision, why it matters, exceptions, and the source.Avoid starting with broad adjectives like clear, polished, or intuitive. Agents need observable decisions. Destructive actions use Verb + Noun is usable. Buttons should be clear is not.# Decision: {name}Status: proposed | accepted | rejectedScope:Decision:Rationale:Evidence:Exceptions:Bad example:Good example:Assumptions:Open decisions:Decision record template.Fill in the fields specific to your surface before expanding to others.Link to heading2. Add an explicit trigger and firm boundariesTell agents when to load the skill in persistent repository instructions, and define the files and surfaces it covers along with the areas it must skip. In separate Next.js evals, agents failed to invoke an available skill in 56% of cases. Test the trigger separately from the guidance, because failing to load the skill and failing to follow a rule are different problems.When shaping, editing, or reviewing user-facing UI,load .agents/skills/product-design/SKILL.md.Applies to:- user-facing pages and components- copy, interaction, accessibility, responsive behavior, and statesSkip:- backend-only work with no user-visible effect- telemetry, generated files, documentation, and marketingAGENTS.md trigger and scope boundaries for the product-design skill.Ask the agent to report which surfaces and references it loaded, then verify that its findings cite those sources.Link to heading3. Separate routing, rules, and evidenceUse a short entry point to identify the surface and load focused references. Organize the details around surfaces and decisions reviewers already discuss: forms, modals, navigation, product vocabulary, workflow states, and cross-surface patterns.Give rules stable IDs and link them to examples and sources. Record shipped examples with both useful decisions and known flaws, and keep missing guidance visible in a coverage-gap list.# {Surface}Load when:Canonical owner:## rule/{stable-id}Scope:Rule:Why:Exceptions:Source:## ExamplesBad:Good:## Coverage gaps- {missing decision or evidence}Rule reference template with stable ID, examples, and coverage gaps.A coverage-gap list makes missing guidance explicit.Link to heading4. Use code for clear rulesIf a linter can identify a problem reliably, enforce the rule there. Use agent guidance when the decision needs product or codebase context. Keep new standards, policy choices, and unresolved product decisions with people.Build training fixtures from documented examples and holdouts from interfaces whose expected edits do not appear in the skill. Test retrieval and application separately, because whether the agent loaded the skill and whether it followed the rule are different questions.Can code identify the failure without rendering?- No: use agent guidance.- Yes: can the rule avoid likely false positives? - No: use agent guidance. - Yes: does the violation have a concrete fix? - Yes: use a linter. - No: use a warning or agent guidance.Needs product or codebase context: use agent guidance.Establishes a new standard or product policy: require a human decision.For either path, add an example or eval that can catch regressions.Decision tree for choosing between a linter and agent guidance.If a rule cannot stay reliable without many exceptions, move it back to agent guidance.Link to heading5. Assign ownership and an update loopReview new evidence regularly, but require human approval before changing the guidance or checks. Keep a decision log that records what changed, why, and which source supported it. Treat new rules as product changes, reviewing and testing each one, and removing those that stop helping.Collector promptYou are the collector. Gather messages, links, files, and nearby context.Write raw artifacts only. Do not score candidates or propose rules.Judge promptYou are the judge. Validate coverage before grouping related evidence.Separate verified facts, inferences, and open questions.Keep every candidate pending. Do not edit the guidance.Human reviewChoose: rule, reference, exemplar, lint rule, eval, coverage gap, or no change.Require stable evidence, explicit scope and exceptions, and an approver.Evidence-review prompts for collector, judge, and human review.Start with one surface and the decisions your team already repeats. Put those decisions where code is written and reviewed, and keep people responsible for what becomes a standard.Link to headingBuild your ownThe hardest part is picking the first surface. Every team has decisions worth encoding. The question is whether they live in someone's head or somewhere agents can find them. If you build something using this pattern or have questions about how we set it up, let us know.
Teaching agents product design at Vercel
Learn how Vercel teaches agents product design with agent skills, lint rules, Vercel Agent code reviews, evals, and a human-led update loop.
3,199 words~15 min read