
Here's the scoreboard. Same 50 emails, same prompt, same 4-tier task:
Model
Accuracy
Note
google/gemini-2.5-flash
Here's the scoreboard. Same 50 emails, same prompt, same 4-tier...
Here's the scoreboard. Same 50 emails, same prompt, same 4-tier task:
Model
Accuracy
Note
google/gemini-2.5-flash

TL;DR Last week I benchmarked 5 open-weight models (Llama 4 Scout, Llama 3.3 70B, Qwen3...

These two chatbots are more closely matched than expected

Honestly, when I first saw the numbers I didn't believe them. DeepSeek V4 Flash at $0.25/M output vs...
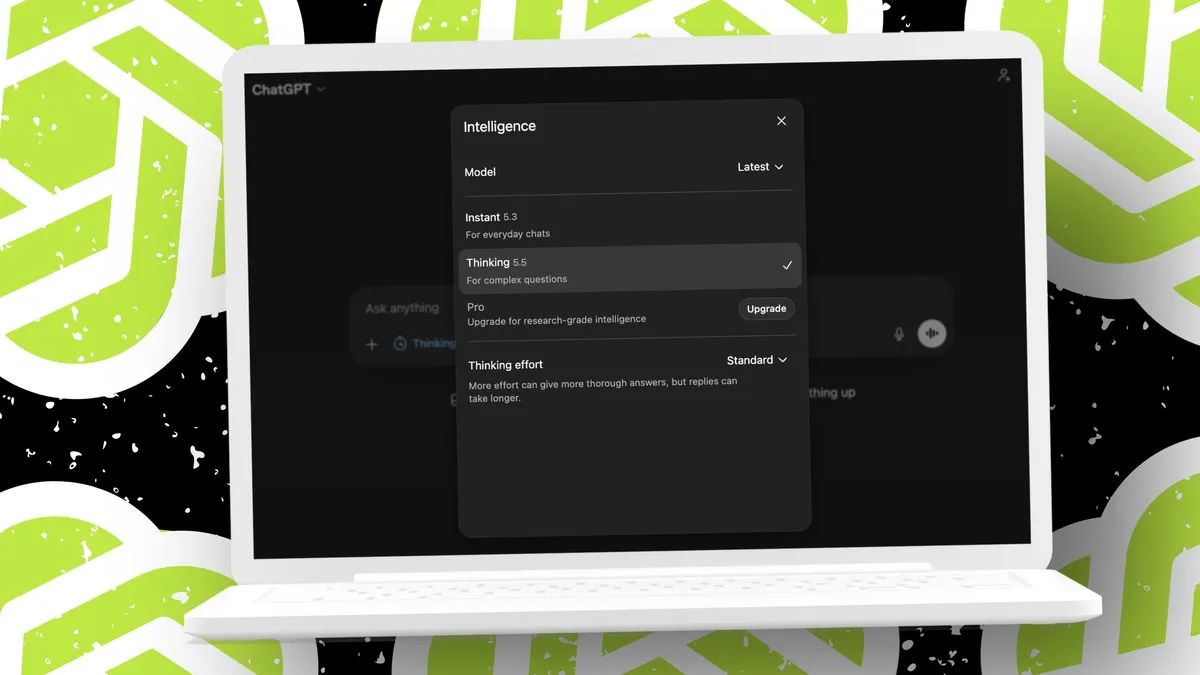
OpenAI's latest model delivers powerful results but sometimes ignores simple directions, creating a tension between intelligence…
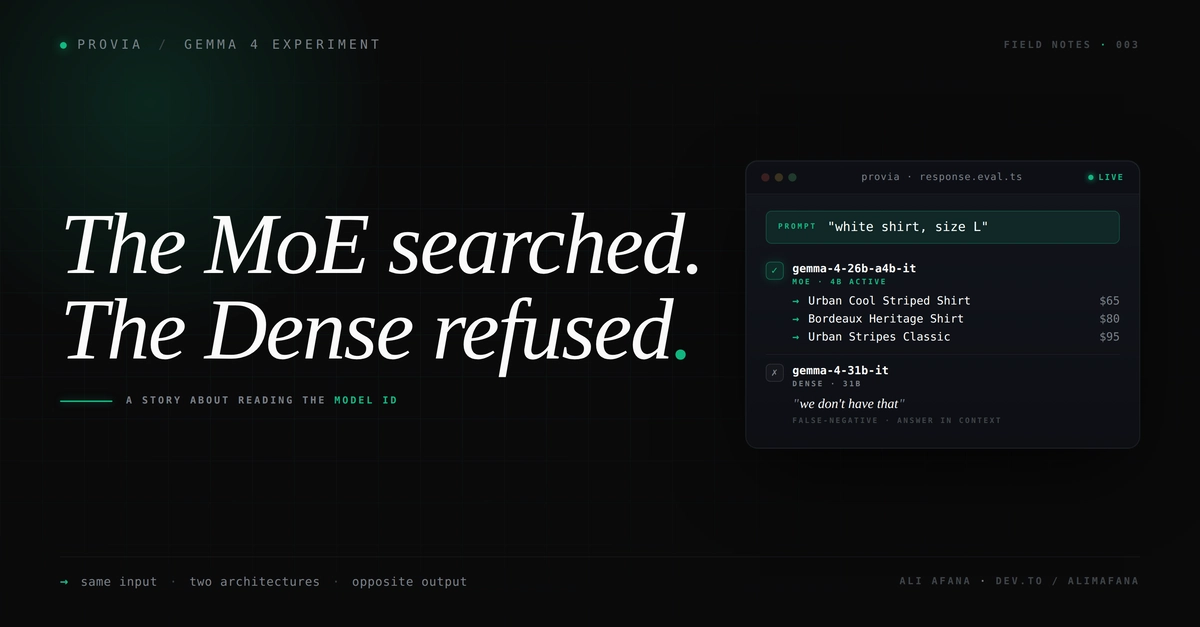
I ran Gemma 4 26B (MoE, 4B active) and Gemma 4 31B (dense) against GPT-4o and GPT-4o mini on a real Arabic e-commerce chatbot.…

Comparing Gemini 3.5 Flash, Claude Haiku 4.5, and GPT-4o mini with migration code and honest tradeoffs from production use.
