I almost shipped a RAG pipeline that, on certain questions, cited exactly the right document — and then told the user the answer wasn't in it.
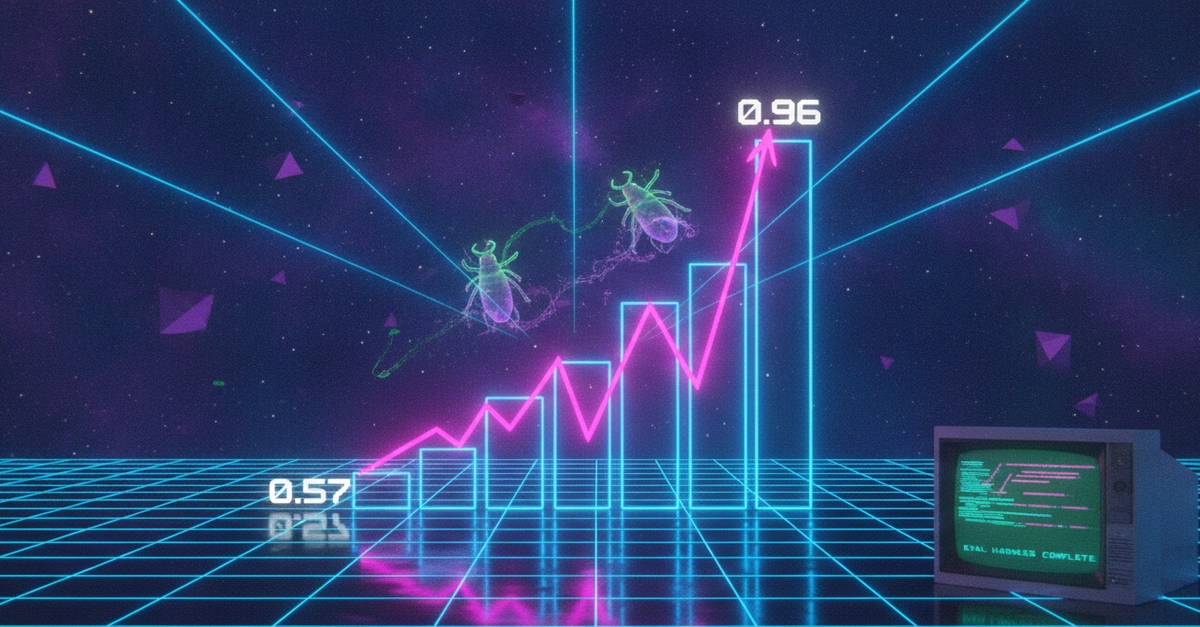
Every unit test was green. The retrieval returned the correct chunk. The API returned 200. The citation was attached to the response. By every check I had, it worked. The first run of my eval harness scored it 0.57, and that number is the only reason I found out before users did.
This is the story of those two bugs, why no unit test I could have written would have caught them, and why I now believe an eval harness belongs in a GenAI project from day one — not "once it's stable."
What the eval harness actually does
For the RAG starter I was building, "chat with your documents," I wanted a test that exercised the thing users actually do, end to end. So the harness:






