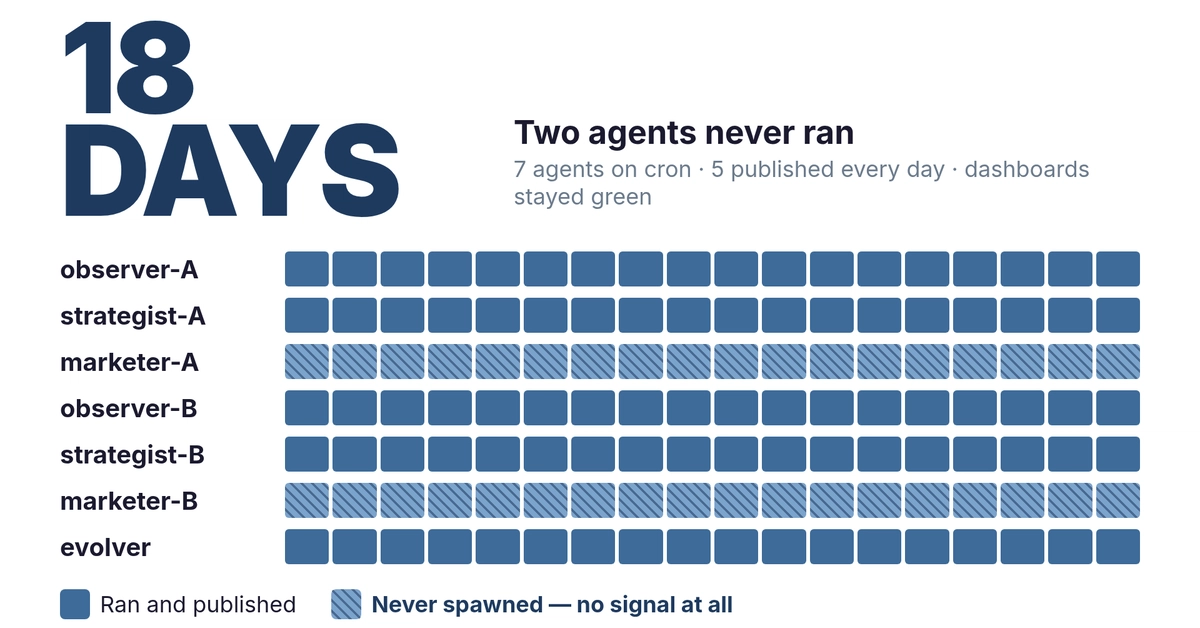
A multi-agent research system sat in production for eleven days doing exactly what it was built to do. Four agents, LangChain-style, coordinating over A2A to pull market data and summarize it. Every health check passed the whole time. No crash, no 500, no timeout... from the outside the system was perfectly healthy.
Two of the four agents had quietly locked into a recursive loop, passing clarification requests and verification instructions back and forth, thousands of times, around the clock. Nobody noticed because nothing was technically wrong. The thing that finally caught it was a person opening the invoice and asking why the number was so high. The number was $47,000.
That story has been making the rounds because it's so relatable, but it isn't a one-off. Uber said it burned through its entire 2026 AI coding budget in four months. One company reportedly ran up a $500M Claude bill after rolling out access with no usage caps. The FinOps Foundation said that around April, the conversation across the industry flipped from "go fast" to "we need guardrails, how do we control this." This is the dominant operational failure mode in production agents right now, and it's barely about the model at all.