
A Transformer Decoder does not generate a sentence all at once.
It predicts one token.
Then it feeds that token back and predicts the next one.
That simple loop is the core of modern LLM generation.
Core Idea
A Transformer Decoder does not generate a sentence all at once. It predicts one token. Then it...
A Transformer Decoder does not generate a sentence all at once.
It predicts one token.
Then it feeds that token back and predicts the next one.
That simple loop is the core of modern LLM generation.
Core Idea

Transformers changed AI because they stopped reading sequences one token at a time. Instead of...
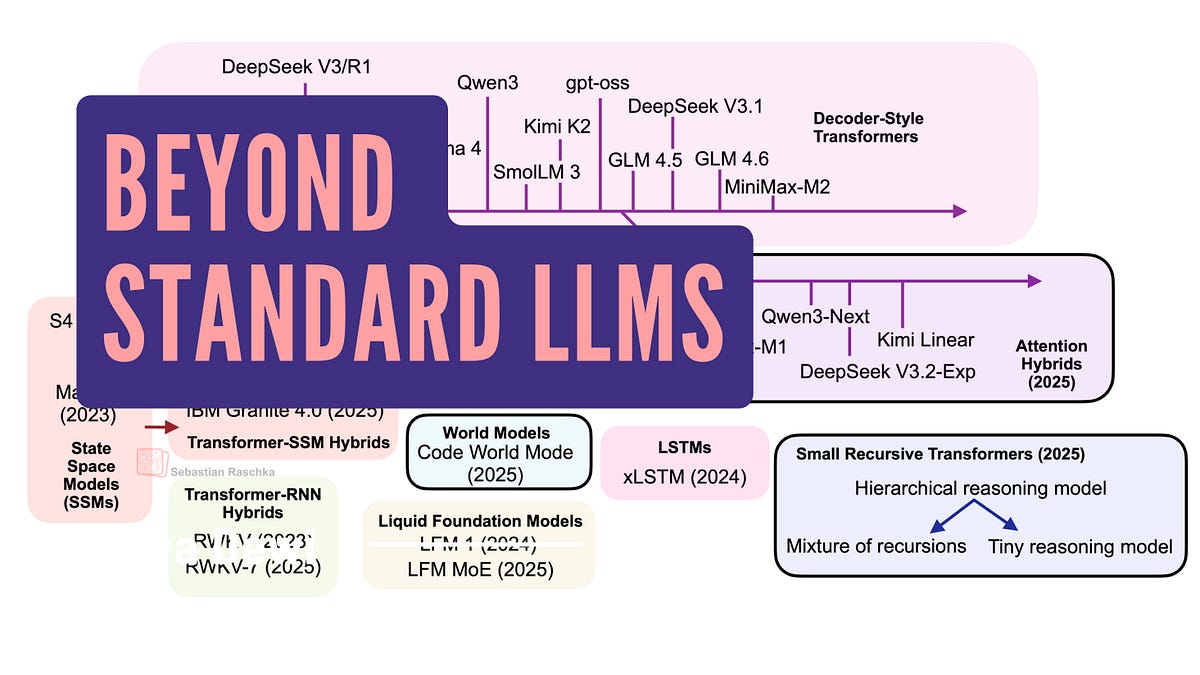
Linear Attention Hybrids, Text Diffusion, Code World Models, and Small Recursive Transformers
In the context of the Transformer model, which is widely used across LLMs, decoding refers to the process of generating an output…

The original Transformer idea is still alive. But modern LLM blocks are not just the 2017...

BERT reads everything at once and understands. GPT reads left to right and predicts what comes next....

Inside one of the msot promising non-transformer architectures.
