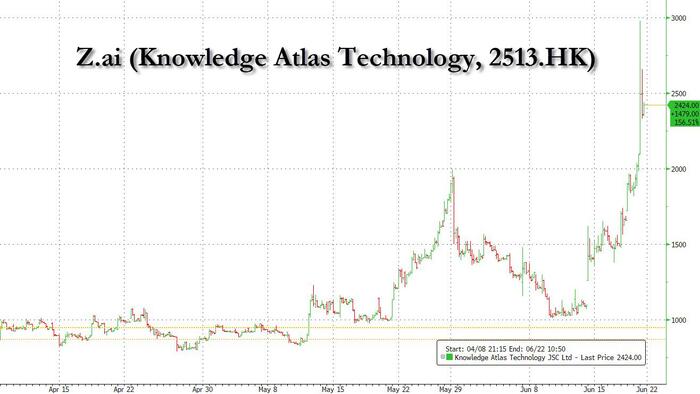
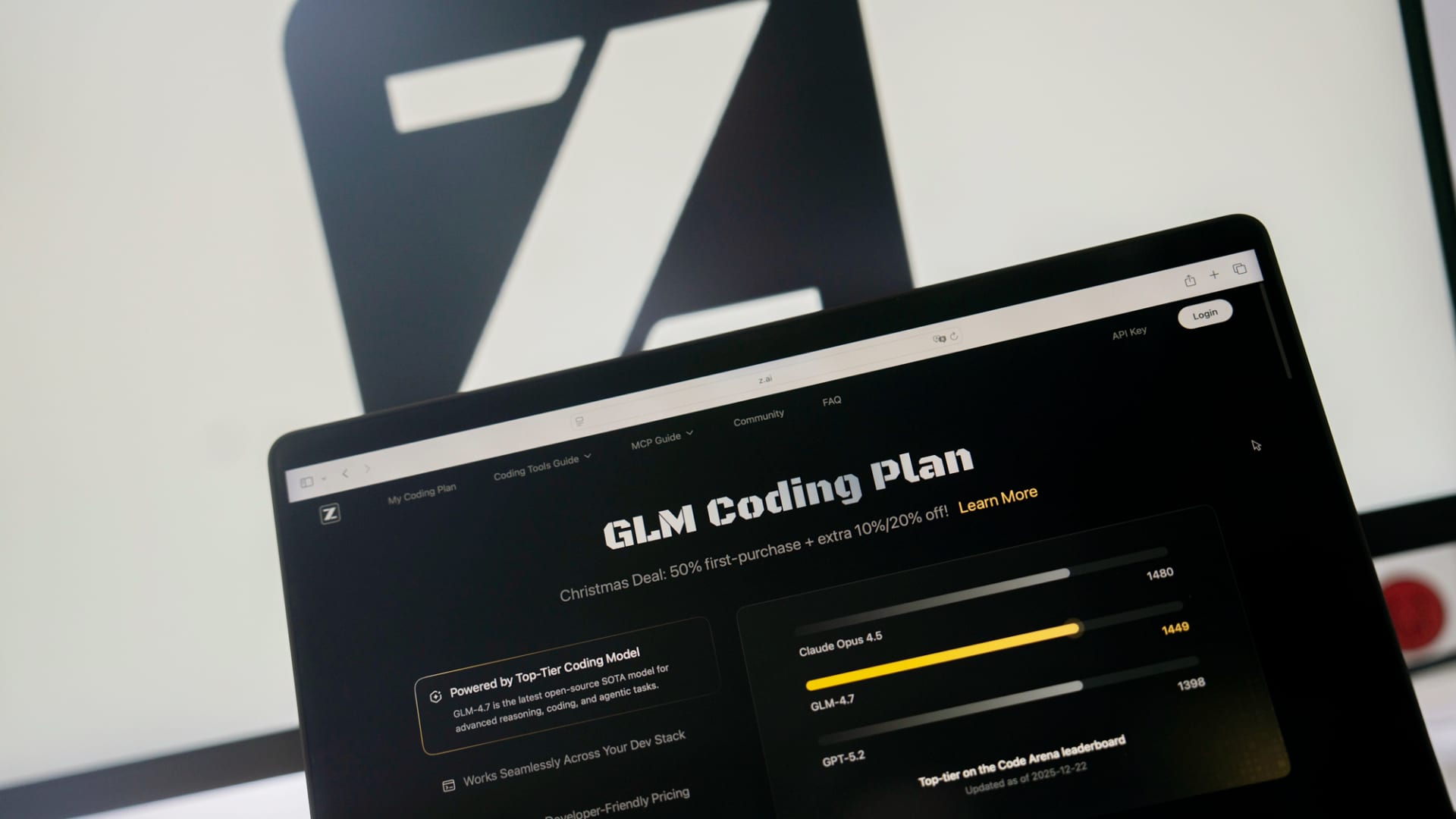
For much of the past decade, the narrative of global artificial intelligence was essentially a story about American dominance. The foundational models, the breakthrough research, the dominant platforms, the headline valuations, nearly all of it originated in a handful of laboratories clustered along the US’ Pacific coast.The rest of the world, including China, was understood to be catching up at varying speeds, separated from the frontier not merely by months or years but by what many analysts believed was a structural, perhaps insurmountable, technical gap.That assumption deserves to be revisited. Carefully, and urgently.The release of GLM-5.2 by Chinese AI company Zhipu AI this week is the latest, and arguably the most consequential, signal that China’s AI sector has entered a new phase of maturity and global competitiveness. It is a development that merits sober analysis, not breathless headline writing, but not dismissal either.What GLM-5.2 actually isAt its technical core, GLM-5.2 is a large language model built on a Mixture-of-Experts (MoE) architecture. It has approximately 744 billion total parameters but activates only around 40 billion of them per token, a design choice that delivers the reasoning depth of a truly large model at a fraction of the computational cost of activating the full network. This efficiency-first philosophy, pioneered in the Chinese AI context by DeepSeek and now carried forward by Zhipu, is increasingly defining the direction of the industry globally.The model supports a context window of one million tokens, the equivalent of being able to hold entire books, large software codebases, or extensive legal document sets within a single conversation without losing coherence. It performs strongly in mathematical reasoning, code generation, debugging, and multistep agentic workflows. Independent evaluators have placed it among the most capable open source AI systems currently available.Crucially, GLM-5.2 is released under an MIT open source licence. Any developer, organisation, or institution can download it, run it locally, modify it, fine tune it on proprietary data, and integrate it into commercial products, without licence fees, API dependencies, or access restrictions imposed by a third party.The DeepSeek precedent and what comes afterTo understand why GLM-5.2 matters, one must revisit the DeepSeek-R1 moment of January 2025. That model’s release was treated, at the time, as a shock, an unexpected demonstration that frontier level reasoning capability could be achieved outside Silicon Valley, at dramatically lower cost, and made freely available to the world. It challenged the assumption that US export controls on advanced semiconductors had effectively constrained Chinese AI development.GLM-5.2 is best understood not as a sequel to that moment but as its logical continuation. Where DeepSeek-R1 proved that China could compete at the reasoning frontier, GLM-5.2 expands that ambition across a wider surface: long context processing at enterprise scale, advanced software engineering, autonomous agent frameworks, and the commercial open source ecosystem.The progression matters. One capable model from one well funded lab might be an outlier. A succession of globally competitive models from multiple Chinese institutions, following a coherent philosophical and architectural trajectory, suggests something more durable: a maturing research and engineering culture with the depth to sustain long-term innovation.The economics of opennessPerhaps the most disruptive aspect of GLM-5.2 is not its intelligence but its business model, or rather, its deliberate absence of one.American frontier AI, from OpenAI, Anthropic, and Google, is overwhelmingly delivered through proprietary APIs. For enterprises deploying these systems at scale across thousands of employees and workflows, the token costs are substantial and growing. Many organisations are beginning to evaluate whether dependence on a small number of expensive, geographically concentrated providers is a strategically prudent position.GLM-5.2 presents a direct alternative. An organisation that deploys it locally bears only the infrastructure cost. It retains full control over its data. It is not subject to access restrictions, policy changes, or pricing revisions imposed by a third party. For start-ups, research institutions, and enterprises in cost sensitive markets, India emphatically among them, this is not an abstract proposition. It is an immediately actionable one.The Chinese strategy here is coherent and deliberate. While American laboratories compete on capability and monetise through access, Chinese labs are competing on openness and monetising, where they monetise at all, on services, fine tuning, and enterprise deployment. It is a different theory of value creation, and it is gaining adherents.Honest caveatsNone of this means the US China AI gap has closed, or that GLM-5.2’s capabilities are definitively established. Much of the early performance data relies on evaluations conducted or curated by Zhipu itself. Independent benchmarking at scale takes time, and the history of AI model releases is full of claims that proved more qualified under rigorous external scrutiny.American frontier models, the most capable systems from OpenAI, Anthropic, and Google, still hold meaningful advantages in certain dimensions of reasoning, multimodal capability, and alignment. The gap at the absolute frontier remains, even if it has narrowed significantly.What has changed is the nature of the competition. The relevant question is no longer simply which model scores highest on a given benchmark. It is which models, under which terms of access, will be adopted at scale by the developers, enterprises, and institutions that will build the next generation of AI powered products and services. On those terms, the contest is far more open than it appeared 18 months ago.What it means for IndiaIndia has no stake in rooting for either side of the US China AI rivalry. It has every stake in ensuring that Indian enterprises, developers, and institutions have access to powerful AI infrastructure on terms that preserve their agency and serve their interests.A world in which frontier capable AI is available only through proprietary American APIs, subject to US government access restrictions and geopolitical risk, is a world in which India’s technology sector is perpetually dependent on external goodwill. A world in which open weight, frontier capable models are freely available for local deployment is a world in which Indian organisations can build on genuine foundations of their own choosing.GLM-5.2 does not resolve India’s AI strategy. But it expands the range of options available to Indian actors, and in a strategic landscape defined by dependency and leverage, expanding the option set matters enormously.ConclusionThe global AI race is entering a new phase. It will be defined less by which nation hosts the laboratory that trains the single most powerful model, and more by which ecosystem, of models, tools, developer communities, enterprise integrations, and deployment infrastructure, earns the trust and adoption of the world’s builders.China’s AI sector has demonstrated, through DeepSeek-R1 and now through GLM-5.2, that it is not merely a participant in that race. It is a shaper of its terms. The gap between Chinese and American AI capability, once measured in years, is now measured in months, and narrowing. The future of artificial intelligence will be more competitive, more open, and far more global than the narrative of American dominance suggested.That is not a threat to be feared. It is a reality to be engaged with, strategically, analytically, and without delay.The writer is a tech and social entrepreneur and Programme Director (Eastern India) at WHEELS Global Foundation, a Pan-IIT alumni initiative working across 20+ states in IndiaPublished on June 23, 2026
The Dragon Codes
How China’s GLM-5.2 signals a new phase in the global AI race
1,182 words~5 min read