Turning a library of aerial imagery into a natural-language-searchable knowledge base is a problem that touches every industry that relies on geospatial data — insurance, real estate, government, infrastructure, and agriculture. The traditional path requires either manual tile-by-tile inspection or training a bespoke computer vision model for each new question. Multimodal embeddings, large language model (LLM) captioning, and vector search on AWS offer a faster alternative: index once, then query using natural language.
We worked with Vexcel, an aerial imagery and geospatial data provider that operates one of the largest aerial imagery programs in the world, to evaluate embedding models, fusion strategies, caption integration, and search methods over multi-view aerial imagery. Using its own sensors and a dedicated fleet of aircraft, Vexcel collects high-resolution data across 45+ countries and territories, delivering orthomosaic imagery, oblique imagery from multiple angles, and elevation models. The data exists, and the use cases are numerous, but turning billions of pixels into answers about the real world requires a faster path.
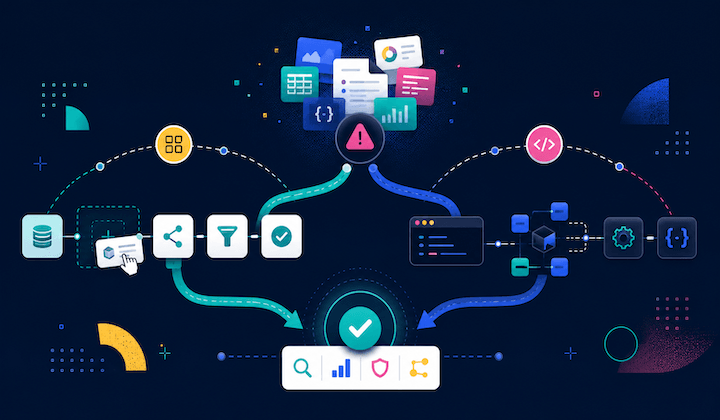
In this post, we walk through the problem space, our architecture on Amazon Bedrock and Amazon OpenSearch Serverless, the evaluation methodology we built on OpenStreetMap ground truth, four experiments that compared embedding models, fusion strategies, captioning, and search methods, and the practical guidance you can apply when building a similar system. You’ll learn which design choices move the needle for geospatial semantic search, including why Amazon Nova Multimodal Embeddings delivered the highest F1 scores across both benchmark queries in our evaluation. The work described here evolved into Vexcel Intelligence, a searchable imagery product.