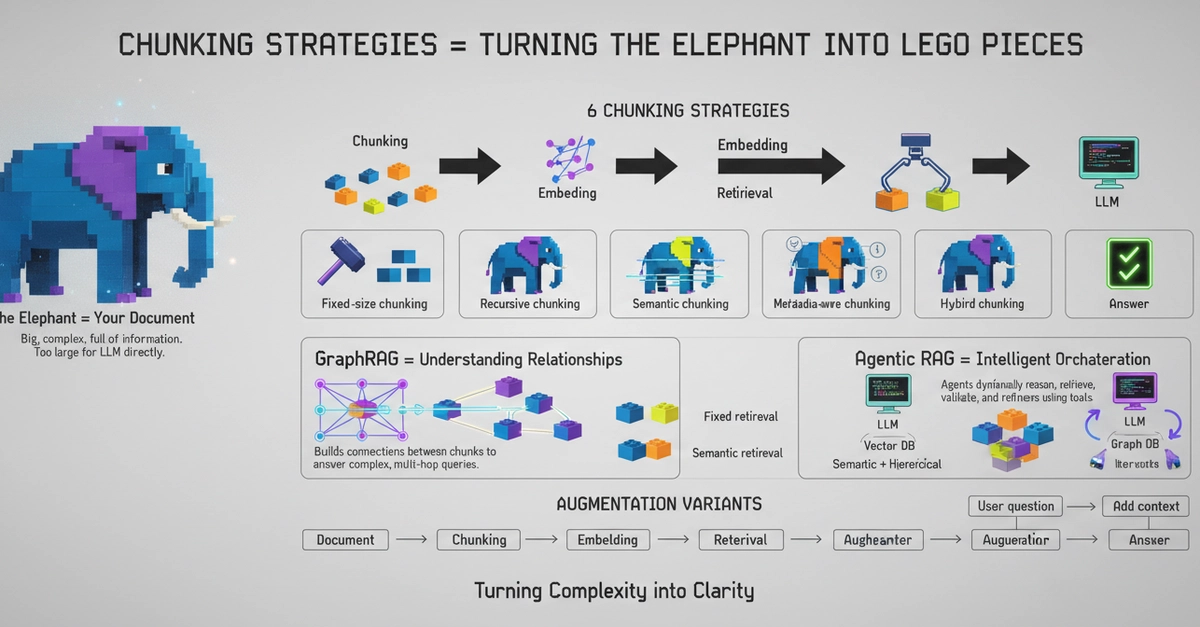
The chunk size forum thread is 47 replies long. Everyone's arguing about 512 vs 1024 tokens, hybrid search vs pure vector, whether reranking actually helps. You're sitting there with a LangChain pipeline that's "production-ready" according to the tutorial, and your retrieval accuracy is 34%. You don't know why. You picked the chunk size because a blog post said so. You don't actually know what semantic chunking does to your embeddings.
That's not a tooling problem. That's a fundamentals problem.
I spent three weeks rebuilding a RAG pipeline from scratch last quarter—not because I needed another RAG pipeline, but because I inherited one that was quietly failing in production. The previous team had followed every "best practice" in the documentation. The vector DB was properly indexed. The LLM calls were cached. The retrieval was... a black box. And when the business users started complaining about hallucinations on specific query types, nobody could explain why.
This is the RAG tax nobody warns you about: Layered Abstraction Debt. When you stack libraries without understanding the layers beneath them, you're not just borrowing convenience—you're borrowing blindness. The system works until it doesn't, and then you can't debug it because you never built the mental model.