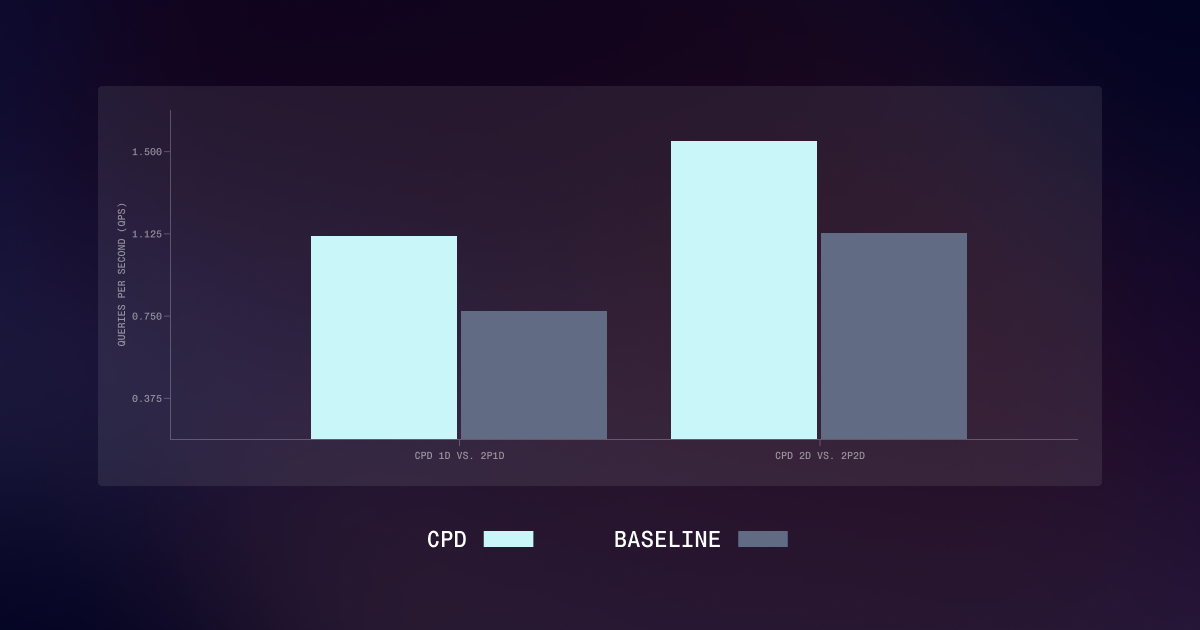
PACI removes the bubbles that cripple asynchronous pipeline parallelism and shaves as much as 1.69× off time‑to‑accuracy compared with the fastest synchronous flush baseline. The paper demonstrates this gain on GPT‑2 Medium pre‑training while preserving the same peak memory usage. By locally accumulating gradients, PACI limits how far a micro‑batch can drift from the current weight version, so the pipeline stays fully busy without any global synchronization.
Before PACI, the dominant strategy was the 1F1B‑flush schedule: it guarantees forward/backward weight consistency but forces empty slots whenever stages wait for gradients to return. Asynchronous alternatives avoided those idle cycles but required heavyweight tricks such as weight stashing, version prediction, or duplicate parameter copies, and they often suffered from unstable training dynamics. The community therefore treated bubble‑free execution as a trade‑off against convergence reliability.
PACI matches the stability and final perplexity of synchronous 1F1B‑flush, retains the same peak memory footprint, achieves fully utilized pipeline throughput, and improves training time‑to‑accuracy by up to 1.69× over the fastest flush baseline [1]. In the reported GPT‑2 Medium experiments the method reduced the wall‑clock time to reach a target perplexity by 1.69×, showing that bounded inconsistency can be exchanged for substantial efficiency without sacrificing model quality.