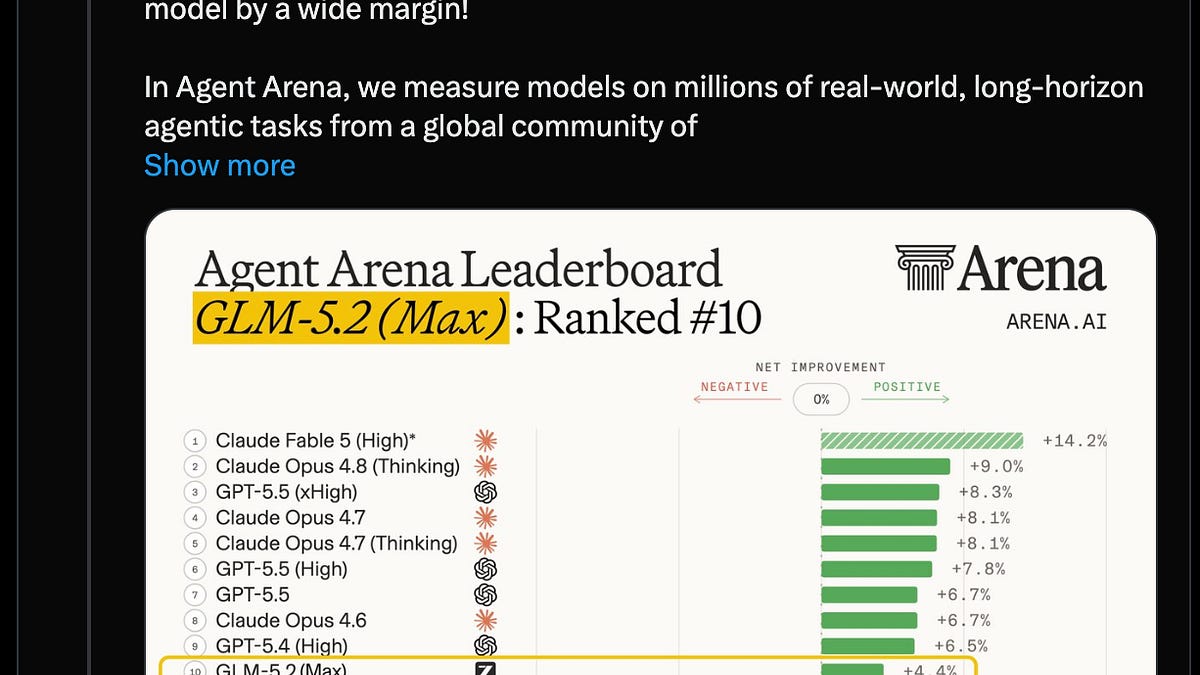
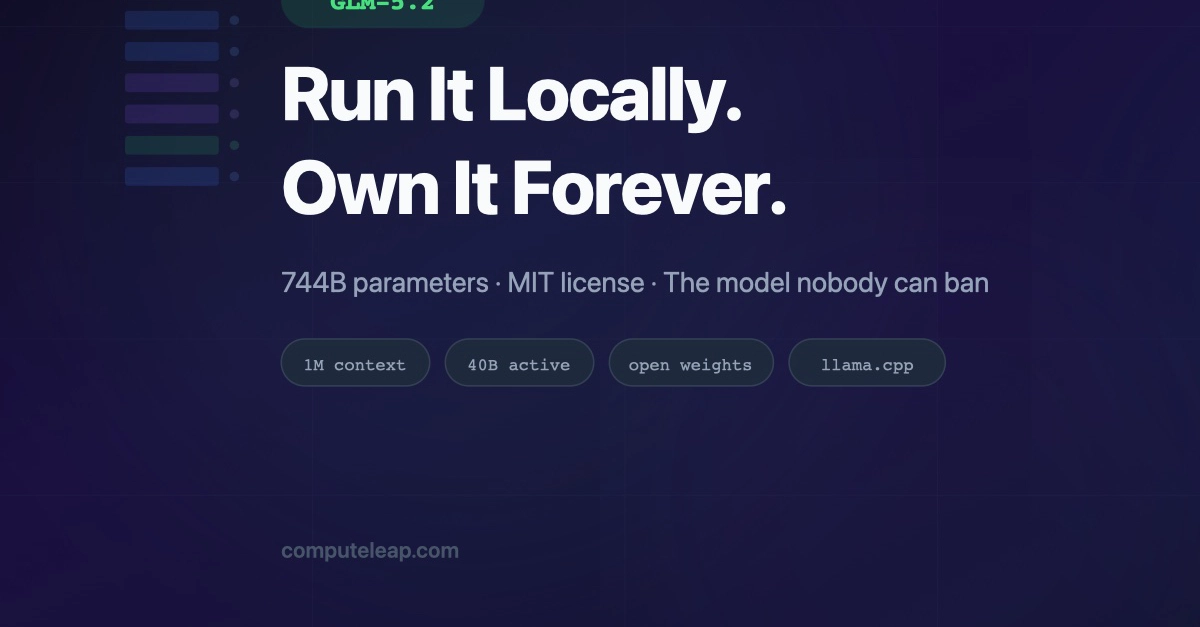
Running a model with roughly 744 billion parameters is not something you do on a single graphics card. Virtuals Protocol just partnered with Leyten to make sure it doesn’t have to.
The AI agent platform has integrated Leyten’s shard engine, a system designed to distribute large-model inference across multiple GPUs over a network. The immediate target: running GLM-5.2, the open-weight model from Z.ai that dropped publicly under an MIT license on June 16, 2026. The combination gives Virtuals a path to frontier-scale AI inference without relying on centralized cloud providers or single massive GPU clusters.
What GLM-5.2 actually is, and why it matters here
GLM-5.2 is a big model. We’re talking approximately 744 billion total parameters, though only around 39 to 40 billion are active per token. In English: the model uses a mixture-of-experts architecture that keeps most of its knowledge stored but only fires up a fraction of it for any given task, keeping compute costs manageable despite the enormous overall size.
The model also ships with a context window of 1 million tokens. That’s five times larger than its predecessor, GLM-5.1.