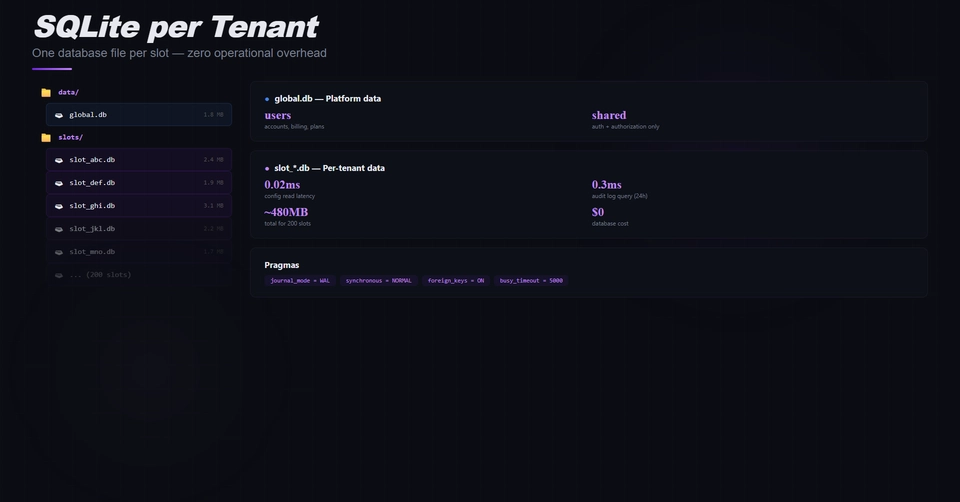
For a long time, our default answer to "how should we structure tenant data?" was Schema-Per-Tenant. And that wasn’t really because the other options were bad, but one had a cost problem that was hard to argue around.
Database-Per-Tenant gives you the cleanest isolation possible. Each tenant lives in a completely separate database.
No shared resources. No WHERE tenant_id = clause you have to trust across every query your team writes for the next five years + a compliance story that actually holds up when someone from legal asks you to explain it.
Honestly, I think we knew all that. Yet, we kept steering people away from it because the bill for running hundreds of idle database instances actually hurt.
Serverless Postgres changed that. When compute scales to zero on idle databases, the cost model for Database-Per-Tenant looks very different for products where most tenants aren't active simultaneously. The thing we kept citing as “dealbreaker” now depends heavily on your usage patterns.