LLM Self-Preference Bias: How Anonymized Peer Review Fixes It
The panel had been agreeing with itself for a week before I noticed, and the worst part is that the logs looked healthy the whole time.
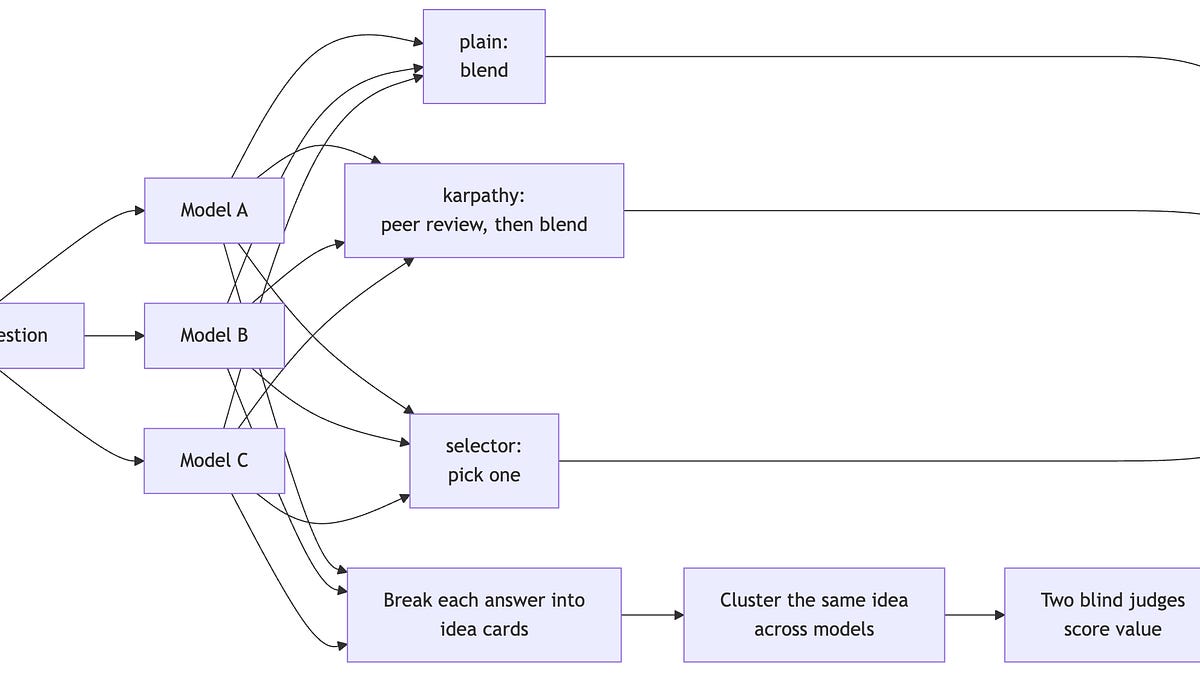
I had built what felt like a clean idea. Several frontier models, different families, each one judging a pool of candidate outputs and ranking them best to worst. A jury of machines. I would generate a handful of answers, let the panel vote, take the winner, and trust that five independent opinions beat one. That was the whole pitch I had sold myself at 1am, and for a few days it ran without complaint. The rankings came in. A winner emerged every round. The dashboard was green.
Then I started actually reading what won.
The outputs the panel kept crowning were not the sharpest. They were the ones that sounded a particular way. Numbered lists where the content did not need numbering. A certain rhythm to the sentences. A house style. I stared at it for a while before the shape of it landed, and when it did it was a little sickening: my panel was not selecting for quality. It was selecting for resemblance. The judges were rewarding the candidates that wrote the way the judges write. I had built a popularity contest and dressed it up as an evaluation.